
Introduction
Now that we have our production application server setup, a recovery plan, and backups, let’s look into adding monitoring to improve our awareness of the state of our servers and services. Monitoring software, such as Nagios, Icinga, and Zabbix, enables you to create dashboards and alerts that will show you which components of your application setup need attention. The goal of this is to help you detect issues with your setup, and start fixing them, before your users encounter them.
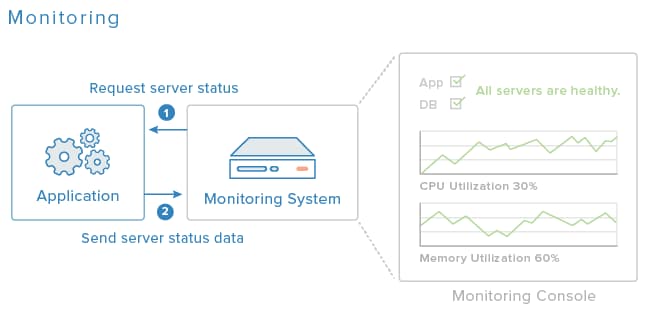
In this tutorial, we will set up Nagios 4 to as the monitoring software, and install the NRPE agent on the servers that comprise our application.
For each server in our setup, we will set up monitoring to check if the server is up and if its primary process (i.e. apache, mysql, or haproxy) is running. While this monitoring guide isn’t comprehensive—you will probably want to set up additional checks that we won’t cover here—it is a great place to start.
Prerequisites
If you want to access your logging dashboard via a domain name, create an A Record under your domain, like “monitoring.example.com”, that points to your monitoring server’s public IP address. Alternatively, you can access the monitoring dashboard via the public IP address. It is advisable that you set up the monitoring web server to use HTTPS, and limit access to it by placing it behind a VPN.
Install Nagios on Monitoring Server
Set up Nagios on your monitoring server by following this tutorial: How To Install Nagios 4 and Monitor Your Servers on Ubuntu 14.04. If you prefer, you may also use Icinga, which is a fork of Nagios.
Stop when you reach the Monitor an Ubuntu Host with NRPE section.
Add Servers to Nagios
On each server in your setup (db1, app1, app2, and lb1), go through the Monitor an Ubuntu Host with NRPE section of the Nagios tutorial.
Be sure to add the private hostname or IP address of your monitoring server to the allowed_hosts setting in NRPE configuration file.
When you are done adding each host, you should have a separate file for each server that you want to monitor: db1.cfg, app1.cfg, app2.cfg, and lb1.cfg. Each file should contain the host definition that refers to the respective hostname and address (which can be the server’s hostname or IP address).
Set Up Host and Service Monitoring
Let’s make a list of common things that we want to monitor on every server. For each server, let’s monitor the following services:
- Ping
- SSH
- Current Load
- Current Users
- Disk Utilization
Let’s set that up now.
Define Common Services
In the Nagios setup tutorial, we configured Nagios to look for .cfg files in /usr/local/nagios/etc/servers (or /etc/icinga/objects/ for Icinga). To keep things organized, we will create a new Nagios configuration file for the common services we want to monitor called “common.cfg”.
First, open the host configuration file for editing
- sudo vi /usr/local/nagios/etc/servers/common.cfg
Add the following service definitions, with the host_name of each of your servers (defined in the host definitions, earlier):
define service {
use generic-service
host_name db1,app1,app2,lb1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name db1,app1,app2,lb1
service_description SSH
check_command check_ssh
notifications_enabled 0
}
define service {
use generic-service
host_name db1,app1,app2,lb1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name db1,app1,app2,lb1
service_description Current Users
check_command check_nrpe!check_users
}
define service{
use generic-service
host_name db1,app1,app2,lb1
service_description Disk Utilization
check_command check_nrpe!check_hda1
}
Save and exit.
Now we’re ready to define the services that are specific to each server. We’ll start with our database server.
Define MySQL Process
Create NRPE Command (on Client)
On your database server, db1, we’ll configure a new NRPE command. Open a new NRPE configuration file, “commands.cfg”:
- sudo vi /etc/nagios/nrpe.d/commands.cfg
Add the following command definition:
command[check_mysqld]=/usr/lib/nagios/plugins/check_procs -c 1: -C mysqld
Save and exit. This allows NRPE to check for a process named “mysqld”, and report a critical status if there is less than 1 processes with that name running.
Reload the NRPE configuration:
- sudo service nagios-nrpe-server reload
Create Service Definition (on Server)
On your Nagios server, monitoring, we need define a new service that uses NRPE to run the check_mysqld command.
Open the file that defines that defines your database host. In our example, it’s called “db1.cfg”:
- sudo vi /usr/local/nagios/etc/servers/db1.cfg
At the end of the file, add this service definition (make sure the host_name value matches the name of the host definition):
define service {
use generic-service
host_name db1
service_description Check MySQL Process
check_command check_nrpe!check_mysqld
}
Save and exit. This configures Nagios to use NRPE to run the check_mysqld command on the database server.
For this change to take effect, we must reload Nagios. However, we will move on to monitoring the Apache process first.
Define Apache Process
Create NRPE Command (on Client)
On your application servers, app1 and app2, we’ll configure a new NRPE command. Open a new NRPE configuration file, “commands.cfg”:
- sudo vi /etc/nagios/nrpe.d/commands.cfg
Add the following command definition:
command[check_apache2]=/usr/lib/nagios/plugins/check_procs -c 1: -w 3: -C apache2
Save and exit. This allows NRPE to check for a process named “apache2”, and report a critical status if there are no matching processes running or report a warning status if there are less than three matching processes.
Reload the NRPE configuration:
- sudo service nagios-nrpe-server reload
Be sure to repeat this on any additional application servers.
Create Service Definition (on Server)
On your Nagios server, monitoring, we need define a new service that uses NRPE to run the check_apache2 command.
Open the file that defines that defines your application host. In our example, they’re called “app1.cfg” and “app2.cfg”:
- sudo vi /usr/local/nagios/etc/servers/app1.cfg
At the end of the file, add this service definition (make sure the host_name value matches the name of the host definition):
define service {
use generic-service
host_name app1
service_description Check Apache2 Process
check_command check_nrpe!check_apache2
}
Save and exit. This configures Nagios to use NRPE to run the check_apache2 command on the application servers. Be sure to repeat this for each of your application servers.
For this change to take effect, we must reload Nagios. However, we will move on to monitoring the HAProxy process before that.
Define HAProxy Process
Create NRPE Command (on Client)
On your load balancer server, lb1, we’ll configure a new NRPE command. Open a new NRPE configuration file, “commands.cfg”:
- sudo vi /etc/nagios/nrpe.d/commands.cfg
Add the following command definition:
command[check_haproxy]=/usr/lib/nagios/plugins/check_procs -c 1: -C haproxy
Save and exit. This allows NRPE to check for a process named “haproxy”, and report a critical status if there is less than 1 processes with that name running.
Reload the NRPE configuration:
- sudo service nagios-nrpe-server reload
Be sure to repeat this on any additional application servers.
Create Service Definition (on Server)
On your Nagios server, monitoring, we need define a new service that uses NRPE to run the check_haproxy command.
Open the file that defines that defines your database host. In our example, it’s called “lb1.cfg”:
- sudo vi /usr/local/nagios/etc/servers/lb1.cfg
At the end of the file, add this service definition (make sure the host_name value matches the name of the host definition):
define service {
use generic-service
host_name lb1
service_description Check HAProxy Process
check_command check_nrpe!check_haproxy
}
This configures Nagios to use NRPE to run the check_haproxy command on your load balancer server.
For this change to take effect, we must reload Nagios.
Reload Nagios Configuration
To reload Nagios, and put all of our changes into effect, enter this command:
sudo service nagios reload
If there are no syntactical errors in the configuration, you should be set.
Check Nagios Services
Before moving on, you will want to verify that Nagios is monitoring all of the hosts and services that you defined. Access your Nagios server via its public hostname or IP address, e.g. http://monitoring.example.com/nagios/. Enter the login you set up during the Nagios server installation.
In the side menu, click on the Services link. You should be taken to a page that looks like this:
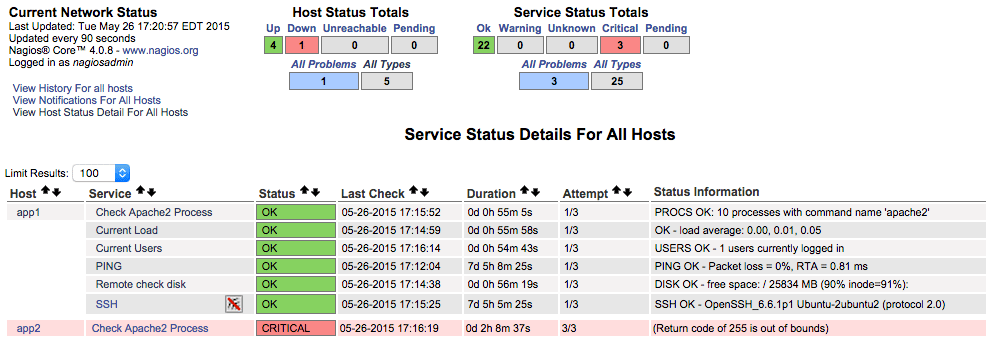
Ideally, you will see each host and all services will be in an “OK” status. In the screenshot, we can see that there is a problem with the app2 server because it was powered off during most recent status checks. If any of your services are not “OK”, fix them or, if the services are fine, review your Nagios configuration for errors.
Other Considerations
You will most likely want to create a recovery plan for your monitoring server, and back up your Nagios configuration files (/usr/local/nagios/etc). Once backups are set up, you will probably want to configure monitoring, for additional services, and email notifications.
Conclusion
Now you should be able to see the status of your servers and services by simply glancing at your monitoring dashboard. In the event of an outage, your monitoring system will help you identify which server(s) and service(s) are not running properly which should help reduce the downtime of your application.
Continue to the next tutorial to start setting up the centralized logging for your production server setup: Building for Production: Web Applications — Centralized Logging.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: Building for Production: Web Applications
This 6-part tutorial will show you how to build out a multi-server production application setup from scratch. The final setup will be supported by backups, monitoring, and centralized logging systems, which will help you ensure that you will be able to detect problems and recover from them. The ultimate goal of this series is to build on standalone system administration concepts, and introduce you to some of the practical considerations of creating a production server setup.
About the author
Software Engineer @ DigitalOcean. Former Señor Technical Writer (I no longer update articles or respond to comments). Expertise in areas including Ubuntu, PostgreSQL, MySQL, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Fantastic tutorial. Im running this production set up at home with virtual Ubuntu 14.04 servers using Oracle’s VirtualBox on a Mac Mini. This really puts to shame Apple’s server software which I think is ok for the faint of heart but rubbish for those of us who prefer a Command Line Interface. My new motto: “If it doesn’t come in a nice clean CLI, I don’t want to know!” Teeshirts to follow :D
Great job Mr Anicas.
Minor issue with Disk Utilization ‘check_disk’ showing error of not being defined.
Minor typo when setting up the config for the application servers on the monitoring server:
“Open the file that defines that defines your database host. In our example, they’re called “app1.cfg” and …”
Should be “application host, no”
Also, for Inciga, the config files are located at /etc/icinga/objects/*.cfg (I know this tutorial focuses on nagios, but Inciga was suggested as replacement at the top)
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
