Note: Pricing and product information correct as of October 3 2025, and subject to change.
Runpod is a runtime platform to support the process of training, fine-tuning, and deploying machine learning models. It provides developers with cloud GPUs that can be quickly scaled across 31 global regions. The platform offers instant clusters for users to launch multi-node GPUs for large-scale AI, ML, or HPC tasks. The serverless feature aims to abstract away infrastructure management. Runpod Hub (still in beta, not production ready) helps one-click deployment of open-source AI projects and community templates.
While Runpod delivers raw compute power at competitive prices, it is not a full end-to-end cloud solution. You still need to choose the right GPU provider that bundles compute with integrated storage, databases, networking, and compliance features to support your production environments. In this article, we’ll explore Runpod alternatives that address these gaps and provide you with options for your AI/ML project.
💡 Key takeaways:
-
With autoscaling, instant clusters, and serverless GPUs, Runpod spins up resources quickly suitable for experimentation and short-term AI/ML workloads.
-
Certification gaps, occasional slow start-ups, and the split in cloud tiers might create uncertainty for long-running or regulated projects using Runpod.
-
Platforms like DigitalOcean, GCP, CoreWeave, Thunder Compute, Northflank, Novita, and Fluidstack offer GPUs with options to integrate storage, networking, databases, and compliance features.
Key features of Runpod
-
Offers autoscaling feature from zero to thousands of workers and FlashBoot technology to reduce cold-start times to under 200 milliseconds.
-
Provides a range of NVIDIA GPUs like H200, B200, H100 (NVL, PCIe, SXM), A100 (PCIe, SXM), L40S, L40, A40, RTX 6000 Ada, RTX A6000, RTX 5090, RTX 4090, RTX 3090, L4, and RTX A5000.
-
Run pipelines with S3-compatible storage, no ingress/egress fees, and support for large-scale data ingestion and processing.
-
Integrated monitoring and orchestration with real-time logs, task queuing, and workload distribution.
On-demand rates start at $1.99–$2.69/hour for H100 configurations, $0.39/hour for L4-class GPUs, $0.33/hour for RTX A6000 and $0.40/hour A40. The pricing information is applicable to ‘Community cloud’.
Limitations of Runpod
Runpod comes with trade-offs that might affect usability, compliance, and long-term reliability. Understanding the following limitations will help you decide whether Runpod is the right fit for your use case.
1. Compliance gaps
Runpod holds a SOC 2 Type I certification for its platform and operations, while its underlying data centers are SOC 2 Type II certified. A Type I report only verifies that the right security and trust controls were in place at a single point in time, it doesn’t confirm that these controls are consistently followed over an extended period. Until Runpod completes its announced SOC 2 Type II audit, customers in regulated industries may face uncertainty about the platform’s long-term compliance posture. Compliance with HIPAA and GDPR are still on their roadmap, which may limit adoption among healthcare, and enterprise clients who need proof of compliance.
DigitalOcean maintains SOC 2 Type II certification across its services, which demonstrates a strong adherence to security and privacy practices over time. DigitalOcean supports compliance with GDPR, HIPAA, and PCI-DSS, making it easier for your businesses in regulated sectors to meet their legal and contractual requirements.
2. Slow cold-starts
Even with FlashBoot technology, some users report that cold starts can be slow with larger models. In some cases, starting a model after inactivity can take minutes, not just seconds, due to downloading weights or re-initializing state.
3. Community cloud vs secure cloud trade-offs
Runpod’s model is split between Community Cloud and Secure Cloud.
-
Community Cloud relies on vetted individual hosts and can be more cost-effective, but it might lack the same redundancy, uptime, and compliance guarantees.
-
Secure Cloud, on the other hand, uses Tier III+ data centers with stricter requirements but comes at a higher cost.
This dual-tier approach creates a trade-off for users: they must choose between affordability and enterprise-grade reliability. It also introduces pricing complexity, since customers need to evaluate not only how much they pay but also whether the tier they choose will meet their compliance and performance requirements in the long run.
💡 Platforms like DigitalOcean avoid the tradeoff between price and performance. All of its services run on standardized, enterprise-grade infrastructure with uptime SLAs. DigitalOcean’s pricing is straightforward and transparent, which makes it easier for teams to plan costs without worrying about hidden trade-offs between cheaper and “more secure” options.
7 on-demand Runpod alternatives for GPU compute
While Runpod might be attractive for experimental AI/ML workloads, it is not always the best fit for every project, when factors like cost, ecosystem integration, or specialized hardware requirements are involved.
1. DigitalOcean Gradient™ AI GPU Droplets
DigitalOcean’s Gradient™ AI GPU Droplets are virtual machine instances for training and inference of AI/ML models, deep learning, analytics, and high-performance computing. Users can provision either one-GPU or eight-GPU configurations. GPU Droplet options are available across AMD Instinct™ MI325X and MI300X to NVIDIA HGX H100, H200, L40S, and RTX 4000 and 6000 Ada Generation cards, depending on performance and memory needs. Choosing a GPU platform like DigitalOcean which integrates high-performance compute with services like block and object storage, managed databases, and Kubernetes can help you build AI workloads without infrastructure overhead.
Key features:
-
Offer prebuilt Ubuntu-based images featuring preinstalled drivers, CUDA/ROCm stacks, NVIDIA container toolkit, and optionally inference-optimized environments. This reduces setup friction for both AMD and NVIDIA GPUs.
-
Includes both a persistent boot disk and, for applicable configurations, a high-capacity scratch disk for temporary data to support workflows like large model training requiring temporary workspace.
-
Backed by compliance standards such as HIPAA eligibility and SOC 2, and come with a 99.5% uptime service-level agreement, offering assurances for reliability and governance.
With a 12-month commitment, H100 × 8 priced at $1.99/GPU/hour. MI325X × 8 costs $1.69/GPU/hour, and MI300X × 8 to $1.49/GPU/hour. On-demand pricing starts at $0.76/hour for RTX 4000 Ada Generation, $1.57/hour for RTX 6000 Ada Generation and L40S, $1.99/hour for AMD MI300X (single GPU), and $3.39/hour for a single H100.
💡Working on an innovative AI or ML project? DigitalOcean GPU Droplets offer scalable computing power on demand, perfect for training models, processing large datasets, and handling complex neural networks.
Spin up a GPU Droplet today and experience AI infrastructure without the complexity or large upfront investments.
2. GCP
With Google Cloud Compute Engine, users can integrate NVIDIA GPUs like GB200, B200, and H200, into VM instances for AI and machine learning workloads. These GPUs can be provisioned in two ways: through accelerator-optimized VM families that come with GPUs already attached, or by manually adding GPUs to general-purpose N1 machine types for greater flexibility. Compute Engine supports deployment with Jump Start Solutions with prebuilt samples for use cases such as dynamic websites, load-balanced VMs, three-tier architectures, or ecommerce applications.
Key features:
-
Predefined accelerator-optimized series (A2, A3, A4, G2) provide built-in GPU configurations, simplifying setup and ensuring performance tailored for Compute Engine.
-
General-purpose N1 instances allow users to manually add GPUs like T4, P4, P100, or V100, enabling more control and fine-tuned customization for specific workloads.
-
GPU VMs can be integrated with tools such as Vertex AI, GKE, and workload schedulers like Slurm for deployment across different environments.
Google Cloud bills GPUs separately from CPU and memory resources. For example, an a3-highgpu-1g instance with a single NVIDIA H100 80 GB GPU is priced at around $11.06 per hour.
-
Explore our detailed guide on the top 7 Kubernetes platforms that rival GKE. Compare features, pricing, and ease of use to find the best fit for your workloads.
-
Feeling overwhelmed by hyperscalers? Dive into our in‑depth comparison of AWS, Azure, and GCP to demystify how these giants differ in cost, services, and performance, and why exploring alternatives like DigitalOcean could be your smartest move.
3. CoreWeave
CoreWeave provides GPU compute instances designed specifically for intensive tasks such as AI model training, inference, high-performance computing (HPC), and rendering. The platform’s architecture is modular, built on composable microservices that support customizable storage, network topologies, and compute patterns reinforced by a MLOps team. The observability tools offer detailed, real-time visibility into GPU and system performance.
Key features:
-
Range of GPUs, from GB200 NVL72 and H200 to A100 and L40S, along with RTX Pro 6000 Blackwell Edition, available in NVL/HGX and PCIe setups.
-
BlueField-3 DPUs dedicated to managing storage and networking operations.
-
Multi-GPU cluster support with InfiniBand and high-bandwidth interconnects, ensuring low-latency communication and optimized distributed training.
GPU instance pricing starts at $49.24/hour for 8× H100, $50.44/hour for 8× H200.
💡Explore top CoreWeave alternatives that match its GPU capabilities, offer smoother integration, better pricing transparency, and more mature compliance and infrastructure guarantees.
4. Thunder Compute
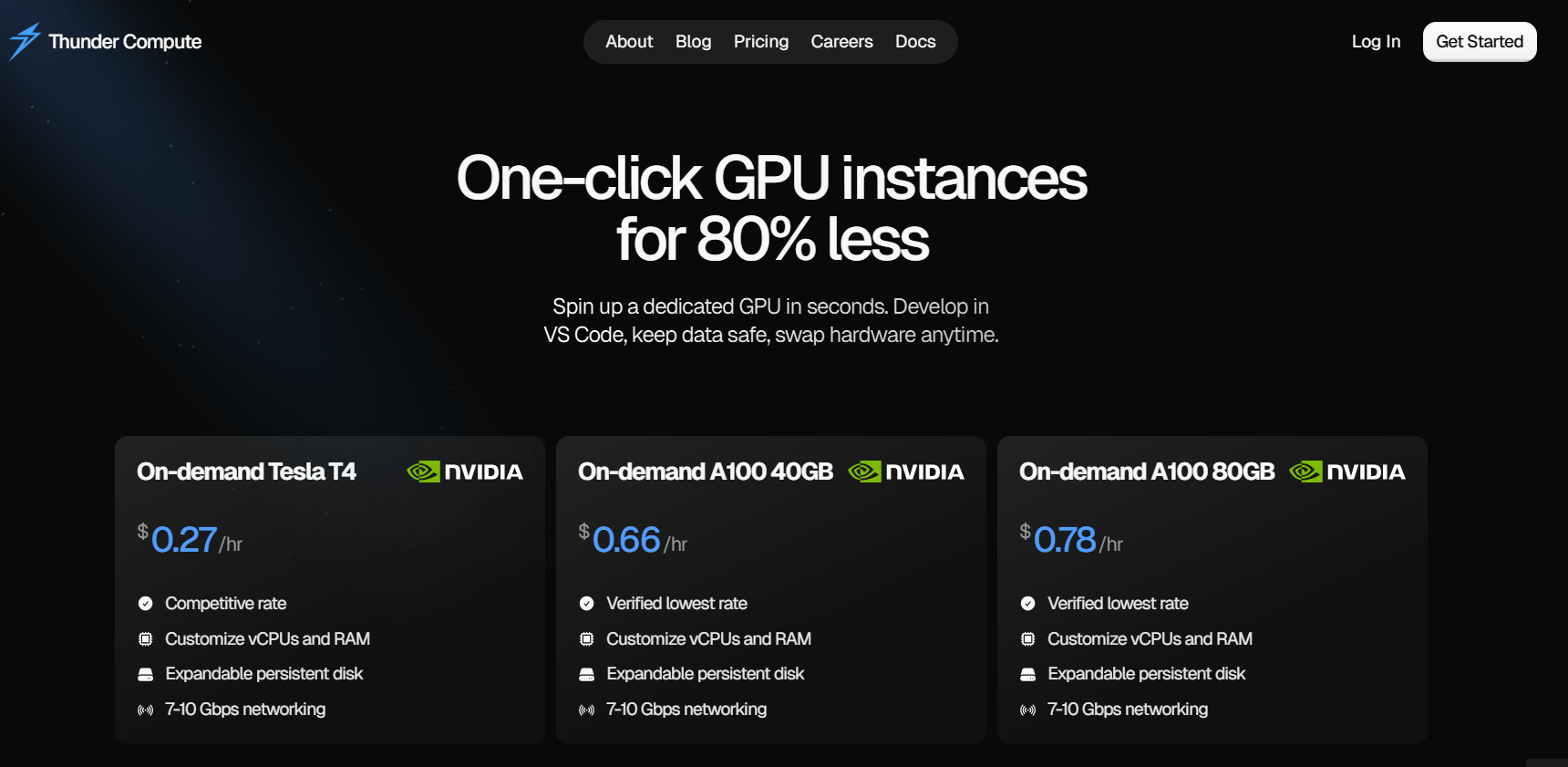
Thunder Compute is a cloud GPU platform for AI/ML workflows. Users can launch NVIDIA-accelerated instances like T4, A100 (40 GB or 80 GB), and H100, on a pay-as-you-go basis with minimal setup, with options optimized for prototyping or production workloads. The platform has instance templates to quickly set up common tools like Ollama, Comfy-ui, and more.
Key features:
-
Offers GPUs over a network interface for GPU sharing across cloud instances while presenting them as locally available to the user environment.
-
Developers can launch and interact with GPU instances directly from within Visual Studio Code using the Thunder Compute extension without traditional SSH key setup and shell commands.
-
Distinguishes between “Prototyping Mode”, with lower costs for experimentation, and “Production Mode,” which offers higher uptime and support for larger-scale, multi-GPU configurations.
NVIDIA A100 (40 GB) costs $0.66 per hour (availability may be limited), and NVIDIA A100 (80 GB): roughly $0.78 per hour.
💡Whether you’re a beginner or a seasoned expert, our AI/ML articles help you learn, refine your knowledge, and stay ahead in the field.
5. Northflank
Northflank is a unified developer platform built to simplify the full DevOps lifecycle, from source code through deployment and scaling, on either its managed cloud or your own infrastructure. Developers can deploy GPUs like NVIDIA H100, A100, T4, L40S, and AMD MI300X on demand to run AI/ML workloads. Features such as time slicing and NVIDIA Multi-Instance GPU (MIG) for GPU sharing and cost optimization. It supports containerized workloads such as apps, databases, GPU-supported AI tasks, inference services, and CI/CD pipelines, all orchestrated via Kubernetes but delivered through abstractions like microVMs and IaC templates. The platform offers real-time logging, metrics, release pipelines, preview environments, and infrastructure automation.
Key features:
-
Supports multiple interaction modes like web UI, CLI, API, and GitOps for teams to choose between visual dashboards or fully automated, script-driven workflows.
-
Infrastructure can be version-controlled and deployed using reusable templates, with GitOps pipelines that automatically update environments when changes are committed.
-
Workloads can run directly on Northflank’s managed cloud or be connected to your own Kubernetes clusters in AWS, GCP, Azure, on-premises, or bare metal, supporting deployment flexibility without tool duplication.
NVIDIA A100 (40 GB) starts at $1.42/hr, and NVIDIA H100 (80 GB) is priced at $2.74/hr
6. Novita
Novita is a scalable AI cloud platform that lowers infrastructure complexity for developers and startups. Novita supports enterprises to deploy custom models under SLAs, backed by globally distributed GPU instances. The platform provides plug-and-play APIs to reduce infrastructure overhead.
Key features:
-
Offers over 200 model APIs, LLMs with text, image, audio, and video capabilities, available under a unified interface with built-in support for plug-and-play deployment and model serving.
-
GPU instances, like A100, RTX 4090, and RTX 6000, are available in multiple regions worldwide, for model deployments closer to end-users.
-
Automatically scales GPU resources to match workload demands.
NVIDIA H100 SXM with 80 GB VRAM spot pricing for 1x GPU starts at $0.90/hr, and On-Demand pricing for 1x GPU at $1.80/hr.
7. Fluidstack

Fluidstack is an AI-focused cloud platform that delivers dedicated GPU clusters with NVIDIA hardware such as H100, H200, B200, and GB200. These clusters are fully managed, meaning deployment, orchestration, and ongoing operations are handled by Fluidstack. Users can deploy thousands of GPUs (e.g., 1,000+ units) in 48 hours or less, useful for quick scaling for intensive workloads like foundation model training or massive inference serving.
Key features:
-
Each cluster operates in a single‐tenant configuration, no shared nodes.
-
Connects GPUs using InfiniBand fabrics, suitable for large-scale training and tight coupling across GPUs.
-
Fluidstack engineers actively manage and monitor each cluster, detailed audit logging, and rapid support with a guaranteed 15-minute response time.
NVIDIA H100 SXM starts at $2.10/hr, and NVIDIA A100 80GB SXM is priced at $1.30/hr
References
Runpod alternatives FAQs
Are decentralized GPU platforms reliable for production workloads? Decentralized GPU platforms like Runpod help lower costs by pooling underutilized GPUs from individuals or smaller operators. While this approach can be effective for experimentation, batch processing, or budget-conscious projects, reliability for production workloads may be less predictable. Variations in uptime, latency, and node performance are common challenges.
Do Runpod alternatives support Jupyter notebooks and ML frameworks? Most Runpod alternatives support Jupyter notebooks and popular machine learning frameworks such as TensorFlow and PyTorch, but the level of integration varies. Some cloud providers provide preconfigured environments with Jupyter and other ML frameworks. On marketplace-style platforms, users may need to configure their own environments, though containers make this manageable.
Which Runpod competitors provide H100 or A100 GPUs? High-end GPUs like the NVIDIA A100 and H100 are widely available across Runpod’s competitors. Providers such as DigitalOcean list A100s or H100s in their offerings, with options for multi-GPU clusters and NVLink-enabled configurations.
Are there cheaper GPU clouds than Runpod for hobbyists? Yes, hobbyists find cheaper options than Runpod by using decentralized or marketplace-based GPU platforms. Vast.ai, for instance, provides access to RTX GPUs at $0.13 per hour, depending on the hardware and availability.
Accelerate your AI projects with DigitalOcean Gradient™ AI Droplets
Unlock the power of GPUs for your AI and machine learning projects. DigitalOcean GPU Droplets offer on-demand access to high-performance computing resources, enabling developers, startups, and innovators to train models, process large datasets, and scale AI projects without complexity or upfront investments.
Key features:
-
Flexible configurations from single-GPU to 8-GPU setups
-
Pre-installed Python and Deep Learning software packages
-
High-performance local boot and scratch disks included
Sign up today and unlock the possibilities of GPU Droplets. For custom solutions, larger GPU allocations, or reserved instances, contact our sales team to learn how DigitalOcean can power your most demanding AI/ML workloads.
About the author
Sujatha R is a Technical Writer at DigitalOcean. She has over 10+ years of experience creating clear and engaging technical documentation, specializing in cloud computing, artificial intelligence, and machine learning. ✍️ She combines her technical expertise with a passion for technology that helps developers and tech enthusiasts uncover the cloud’s complexity.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
