By Adrien Payong and Shaoni Mukherjee

Introduction
Object detection is one of the most important tasks in computer vision. It powers computers to “see”, recognize, and precisely locate objects in images. Thanks to deep learning, the past few years have seen tremendous breakthroughs in object detection. From real-time single-stage detectors like YOLO to high-accuracy two-stage models like Faster R-CNN, you have various models to choose from.
How do you know which is the “best” object detection model for your project? The answer depends on many factors. This guide will discuss what object detection is, the popular object detection algorithms, the key factors to consider when choosing a model, and how to find the most suitable model for your task.
Key Takeaways
- Object detection’s role: It identifies the presence and location of objects within an image or video frame, for applications like autonomous driving, surveillance, healthcare imaging, retail tracking, and robotics.
- Model families: One-stage models (YOLO, SSD, RetinaNet) are designed for speed, and two-stage models (Faster R-CNN) prioritize accuracy over speed. Transformers (DETR, RT-DETR, RF-DETR) now offer high accuracy and competitive real-time performance.
- Recent progress: YOLOv10–12 has made improvements with NMS-free detection, attention modules, and normalization techniques, with gradual gains in accuracy and efficiency. RF-DETR and newer transformer variants have achieved 55–60+ mAP and run at practical FPS on GPUs.
- Choosing factors: The “best” model depends on trade-offs across accuracy (mAP), inference speed, hardware capacity (GPU vs CPU vs mobile), dataset size/domain, and deployment environment (cloud vs edge vs mobile).
Practical guide:
- For real-time applications, consider YOLOv10/12, RF-DETR Nano, and SSD on mobile devices.
- For highest accuracy or research, use Faster R-CNN, RF-DETR, or large transformer variants.
- Balanced accuracy-speed in production: RetinaNet, YOLOv11-x/YOLOv12, RT-DETR.
- Edge/mobile: Nano/small/tiny YOLO models, MobileNet-SSD, with quantization or distillation for efficiency.
What is Object Detection?
Object detection combines two processes: image classification (identifying what is in the image) and localization (identifying where they are located). This unique combination is what makes it a key part of computer vision and the foundation of practical AI systems.
Definition and Role in Computer Vision
Object detection is a computer vision technique that detects objects in an image or video file and also determines their position (often a bounding box).
Object detection algorithms take an image as input and return the position coordinates for each detected object along with its label (e.g., “person”, “car”). This differentiates object detection from image classification (simply categorizing an image) by also specifying the locations of the objects.
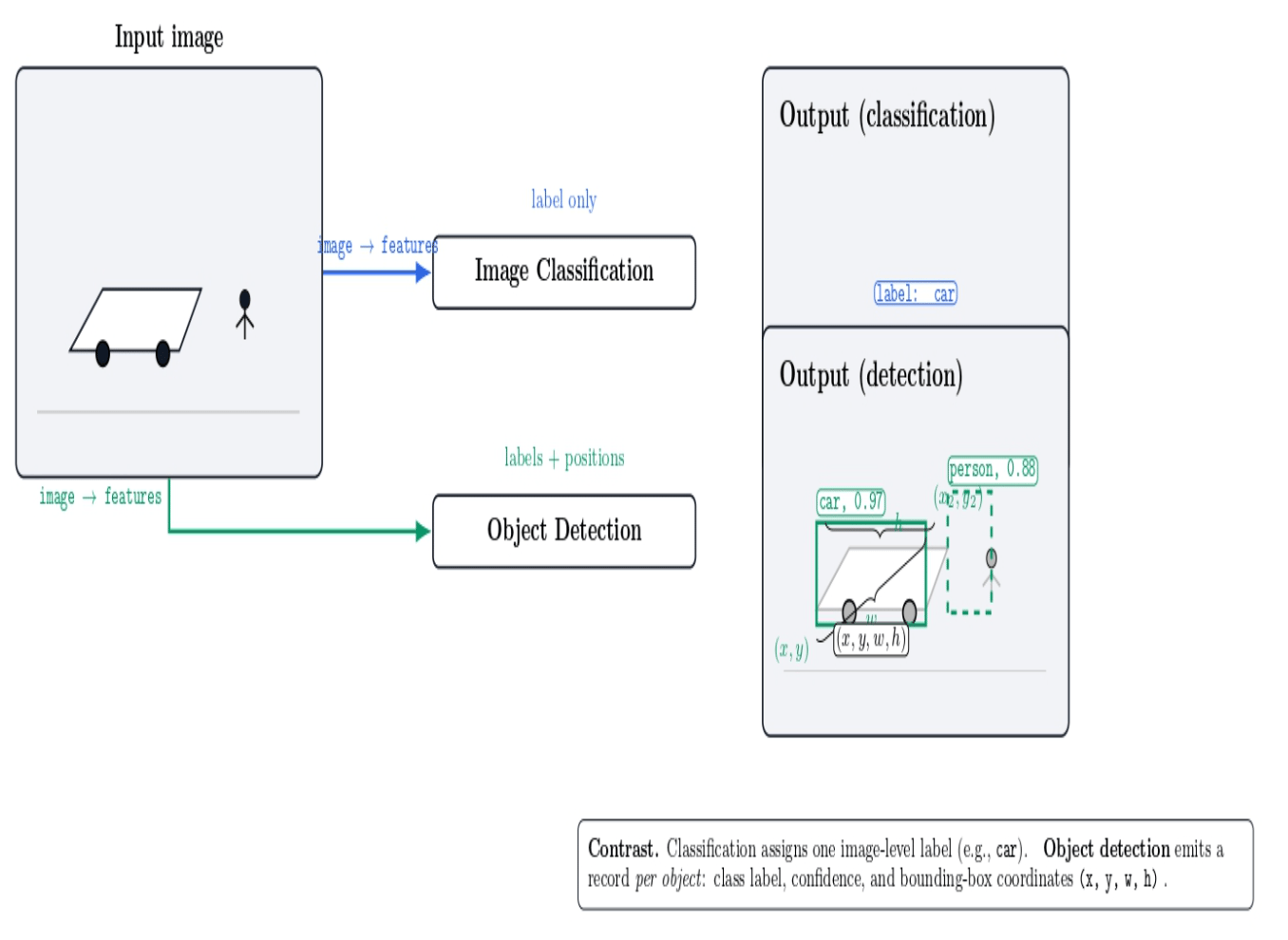
Object detection models generally use convolutional neural networks to extract features from an image. They also use either a single-step (single-stage detector) or a multi-step (two-stage detector) to predict object regions.
Because object detection can describe the “what and where in an image”, it provides computers the ability to understand and interact with the visual world.
Real-World Applications
Object detection finds applications in numerous areas and industries:
- Autonomous Vehicles: Detecting pedestrians, other cars, traffic signs, and obstacles for autonomous/self-driving cars.
- Security and Surveillance: Detecting people or objects in security camera footage (e.g., detecting an intruder or counting people in a crowd).
- Healthcare and Medical Imaging: Locate tumors or other anomalies in medical scans (e.g., lung X-rays to detect nodules).
- Retail and Inventory Management: Monitor store shelves to detect products or empty spaces, as well as tracking customers’ movements.
- Robotics: Enable robots and drones to perceive objects in the world around them to navigate or manipulate items.
Popular Object Detection Models
A large number of object detection algorithms have been proposed throughout the years. However, only a few can be considered state-of-the-art and widely used. We will present some of the most popular ones and their characteristics.
YOLO (You Only Look Once)
YOLO is a family of single-stage object detectors with an exceptionally high speed. As the name of the algorithm suggests, YOLO “looks” at the image once. It splits it into a grid and, in a single forward pass, predicts bounding boxes and class probabilities. This single-stage approach marked a new trend in the development of object detectors and departs from previous two-stage detectors. YOLO is fully convolutional and “looks” at the entire image during training and testing, and performs detection as a direct regression problem without a separate region proposal step.
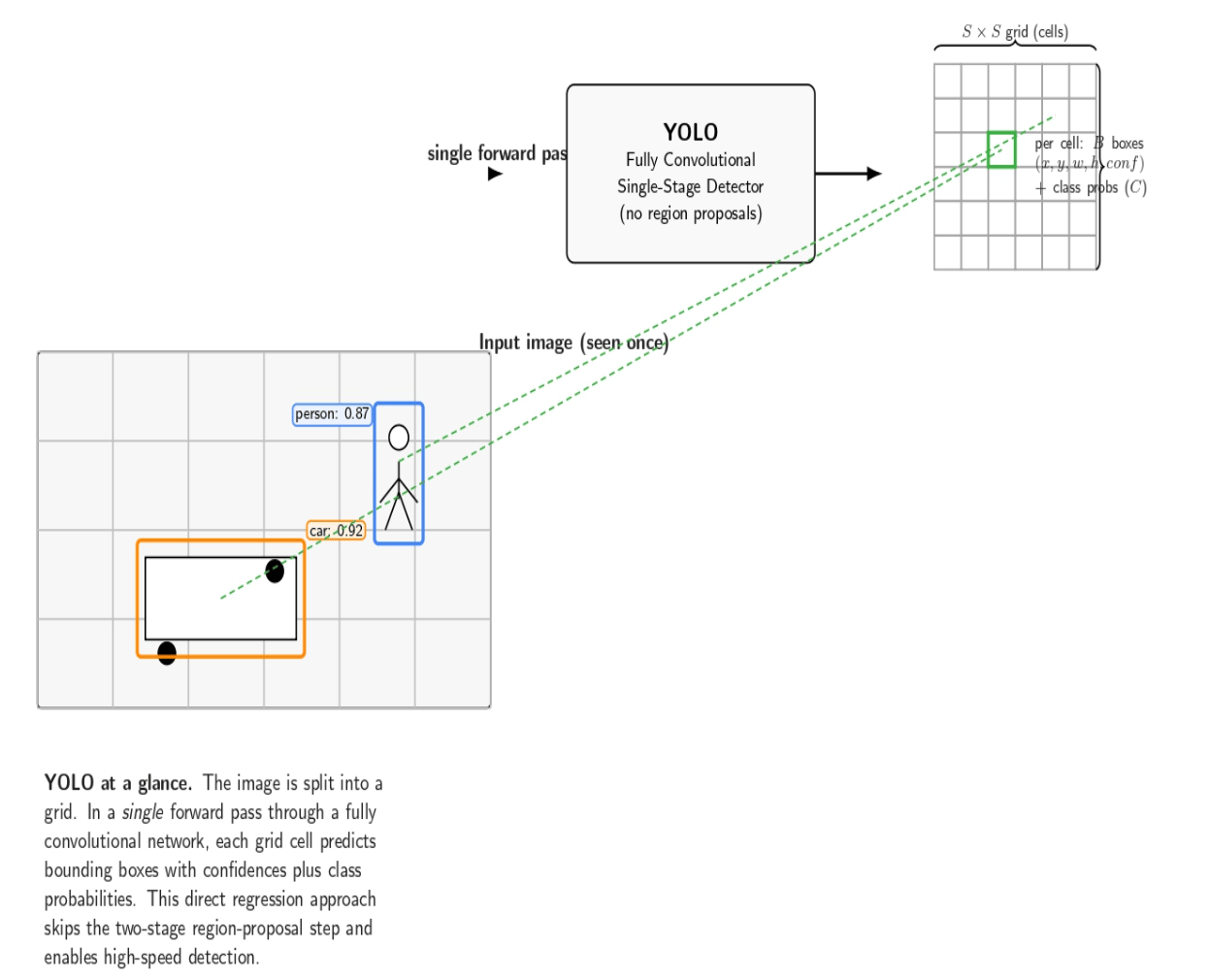
Over several versions (YOLOv1 through YOLOv8, and beyond), YOLO has dramatically improved in accuracy while maintaining real-time speeds.
To get started with YOLO, you can use a pre-trained model or train your own with frameworks like PyTorch. Check out our tutorial for training YOLOv8 on a custom dataset to get a practical understanding.
Faster R-CNN
Faster R-CNN is a two-stage object detector that sets a new milestone in accuracy. As an evolution of the R-CNN series (R-CNN and Fast R-CNN), Faster R-CNN introduces a learnable Region Proposal Network (RPN) to generate candidate object regions. The diagram below displays the general architecture of two-stage object detectors, such as Faster R-CNN:
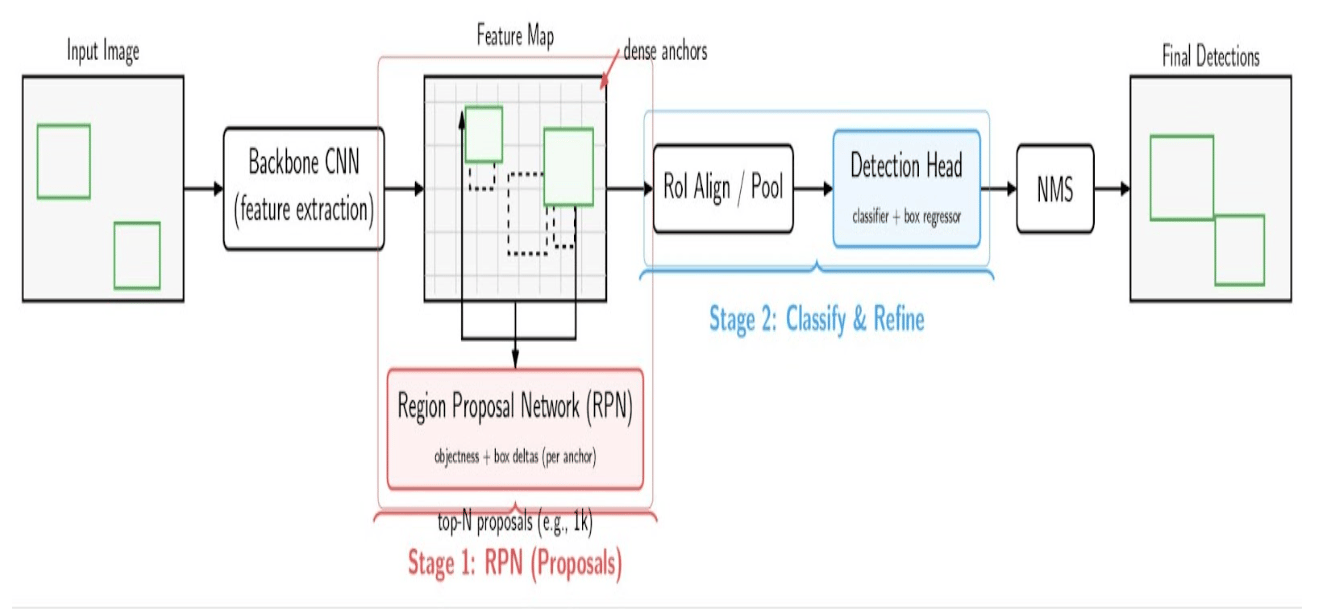
- Backbone CNN: Extract features and output a feature map.
- RPN: Score each anchor for objectness and predict the box offset for dense anchors; Sample top proposals.
- RoI(Region of Interest) Align/Pool: Convert each proposal to fixed-size features.
- Detection Head: Classify each RoI and refine its bounding box.
- Non Maximum Suppression: Filter out overlaps and produce final detections.
The two-step process achieves high detection accuracy, particularly for small or overlapping objects at the expense of more computation.
Faster R-CNN is often used in applications or benchmarks where accuracy (rather than speed) is more important – e.g., for batch processing of images, or applications with complex scenes and high demands on precision.
It is a common baseline in research and is extensible. For example, detection techniques such as Feature Pyramid Networks are often added to the basic model to improve small object detection performance.
RetinaNet
RetinaNet is another one-stage detector, which proposed the Focal Loss to address the class imbalance problem between background vs. object examples. One-stage detectors generate a high number of “easy” negative examples from background predictions, which can easily dominate the training.
RetinaNet’s focal loss function down-weights the loss for negative examples that are already well-classified, allowing the model to focus on the hard, positive examples. RetinaNet was able to achieve the same accuracy as some two-stage detectors for the first time, closing the gap between precision and speed. It uses a ResNet + FPN backbone. Like YOLO, it generates detections in a single pass.
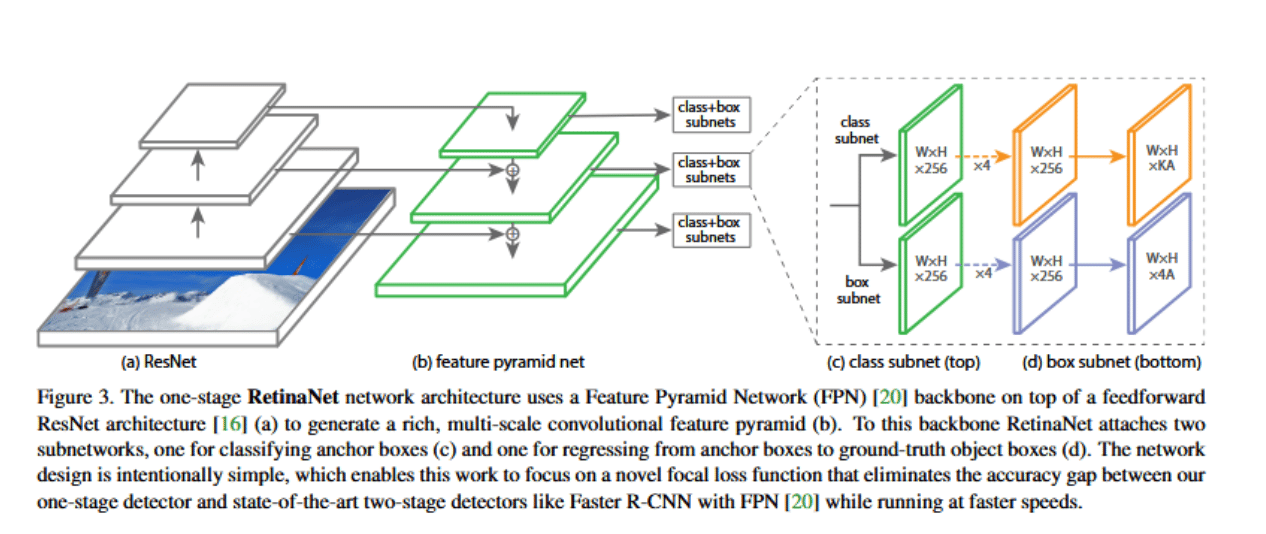
RetinaNet’s accuracy on COCO is typically 35–39% mAP (depending on backbone). The original paper reported ~39.1% mAP with a ResNet-101-FPN. It is simpler and faster than Faster R-CNN, but more accurate than the early versions of YOLO or SSD. It is a great option today if you need a relatively fast detector that can be highly accurate with a simpler training pipeline (one-stage).
SSD (Single Shot MultiBox Detector)
SSD was one of the earliest single-stage detectors (around the same time as the first YOLO versions) to become popular for its speed and ease of use. Let’s consider the following diagram:
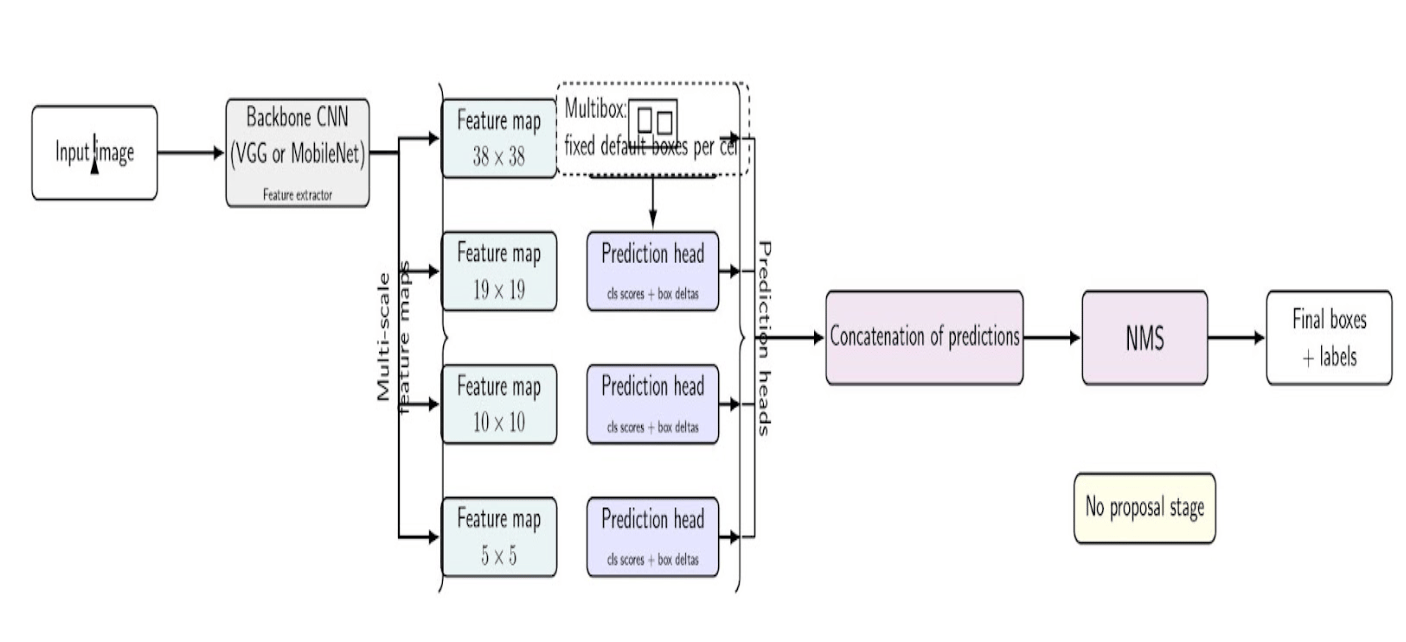
The input is fed to the backbone CNN, which produces multi-scale feature maps. Each of these maps is processed by a prediction head(also called a detection head); in the above diagram, the Multibox arrow only points to a single head for clarity, but it is meant to represent all of the heads conceptually. Their outputs are combined and concatenated, and NMS removes duplicates to produce the final boxes and labels.
Popular Models (YOLOv8, DETR, etc.)
The landscape in 2025 includes some popular architectures that depart from traditional CNN-based designs:
YOLOv8
This is the latest YOLO model from Ultralytics, released in 2023. It builds upon the YOLO concept. However, it further refines and optimizes the backbone, neck, and detection head. YOLOv8 delivers an excellent balance of accuracy and speed. If you are looking for a one-model-fits-all solution that “just works” for real-time detection with good accuracy, YOLOv8 is one of your best bets (See our YOLOv8 article for more in-depth coverage of this model)
DETR (Detection Transformer)
Facebook’s DETR, released in 2020, was the first in object detection to use transformers for the detection task. DETR dispensed with hand-designed anchor boxes and non-maximum suppression. DETR’s output consists of objects and their bounding boxes, and the transformer is used to predict the set of output objects from the set of input image locations. DETR’s pipeline is simpler than previous object detectors, but it requires a substantial amount of training data and time to converge. It is highly accurate for complex scenes with numerous objects or overlapping items, thanks to global self-attention, which can capture contextual relationships.
Transformer-Based Advances
Since DETR, many papers have been published with efficient variants. Deformable DETR introduced sparse sampling to accelerate convergence, while DINO and DN-DETR further improved accuracy. More recently, RT-DETR (Real-Time DETR) has also demonstrated that transformers can match – and even outperform – YOLO in terms of speed.
In fact, a 2023 report shows RT-DETR achieving 53.1% AP at 108 FPS on an Nvidia T4 GPU, surpassing YOLOv8 in both accuracy and speed. Its successor, RT-DETRv2, pushes accuracy above 55% AP without sacrificing speed. This is a significant milestone that narrows the gap between transformer models and CNN models for real-time performance. You may want to use a transformer-based model if you care about state-of-the-art accuracy and have a GPU – latest models provide great accuracy with decent low latency.
Models such as YOLOv9 and YOLOv10 incorporate transformer architectures and hybrid approaches. For example, the YOLOv10 architecture design enables NMS-free detection and an improved backbone, resulting in better speed and accuracy.
YOLOv11 extended this trend by further enhancing efficient blocks (e.g., C3k2), introducing a new spatial attention module, multi-scale context pooling, and additional features, while reducing parameter count from YOLOv8. It also expanded the framework to accommodate various tasks such as segmentation, pose estimation, and oriented bounding boxes.
YOLOv12 doubled down on attention-based design, introducing Area Attention (A²), Residual ELAN blocks, and FlashAttention. Benchmark results show YOLOv12 reaching higher mAP at all scales while maintaining or slightly improving inference latency. At larger scales, it even outperforms RT-DETR variants in speed and parameter efficiency, highlighting the continued evolution of hybrid CNN-transformer approaches.
RF-DETR represents another significant development in transformer-based detection. It was designed as a light yet robust version of DETR. With improvements to query design and training stability, this new model demonstrates that transformer detectors can compete with or even exceed advanced YOLO versions in accuracy. This makes it a more favorable candidate for tasks that require scalability and robustness.
Key Factors in Model Selection
Choosing the right object detection model for your project requires balancing several key factors. Let’s consider them:
Accuracy (mAP and Precision-Recall Tradeoffs)
The accuracy of object detection is usually measured as mAP (mean Average Precision). mAP is a summary metric across the precision-recall curve for object detection, and the standard used in popular datasets such as COCO. A higher mAP means the model detected more objects and made fewer false positive predictions.
mAP computes the average precision scores for each object class. For each object class, it integrates precision and recall across various detection thresholds (based on the Intersection over Union). The resulting AP values for all classes are then averaged to give the mAP value.
Speed (Inference Time and Real-Time Use)
Inference speed (how fast the model can process images) is often as essential as accuracy. Speed is typically measured in frames per second (FPS) or milliseconds per image. A model that runs at 30 FPS or higher on your target hardware is considered real-time for video applications. Speed depends on the complexity of the model and the hardware it’s running on.
Hardware Requirements (CPU vs GPU)
Choosing the right model for your computing budget is the key to achieving smooth performance.
- GPU: Most models can reach their advertised speed with a fast NVIDIA GPU. If you have a GPU (desktop or cloud), you can consider larger models such as YOLOv8x or Faster R-CNN.
- CPU-only or Edge Devices: If you want to run in CPU-only mode (e.g., on a stand-alone embedded board or a mobile phone without a GPU/accelerator), you will use smaller and more efficient models. YOLOv5, YOLOv6, YOLOv7 … YOLOv12 come with Nano and Small versions that are specifically designed for this use case, and can achieve reasonable speeds (typically in the range of tens of FPS at 320×320 resolution) on modern CPUs. In practice, the newer nano models such as YOLOv12n can achieve around 2–3× the accuracy of the older tiny versions (e.g., YOLOv4-tiny) at a similar speed. However, classic lightweight networks such as MobileNet-SSD or Tiny YOLO (YOLOv4-tiny, YOLOv7-tiny) can still be used on low-power devices in cases where compatibility and simplicity are priorities.
- Memory: Larger models use more RAM/GPU VRAM. A large model such as Faster R-CNN with ResNet-101 and FPN may consume several gigabytes of VRAM, while a smaller model like YOLOv8n may only take up a few hundred megabytes.
You can acquire a solid foundation in our PyTorch 101 guide, which will also help to deploy and test these models on appropriate hardware.
Dataset Size and Type
The characteristics of your training data (and target data) influence which model will perform best. This section discusses the important dataset factors to consider:
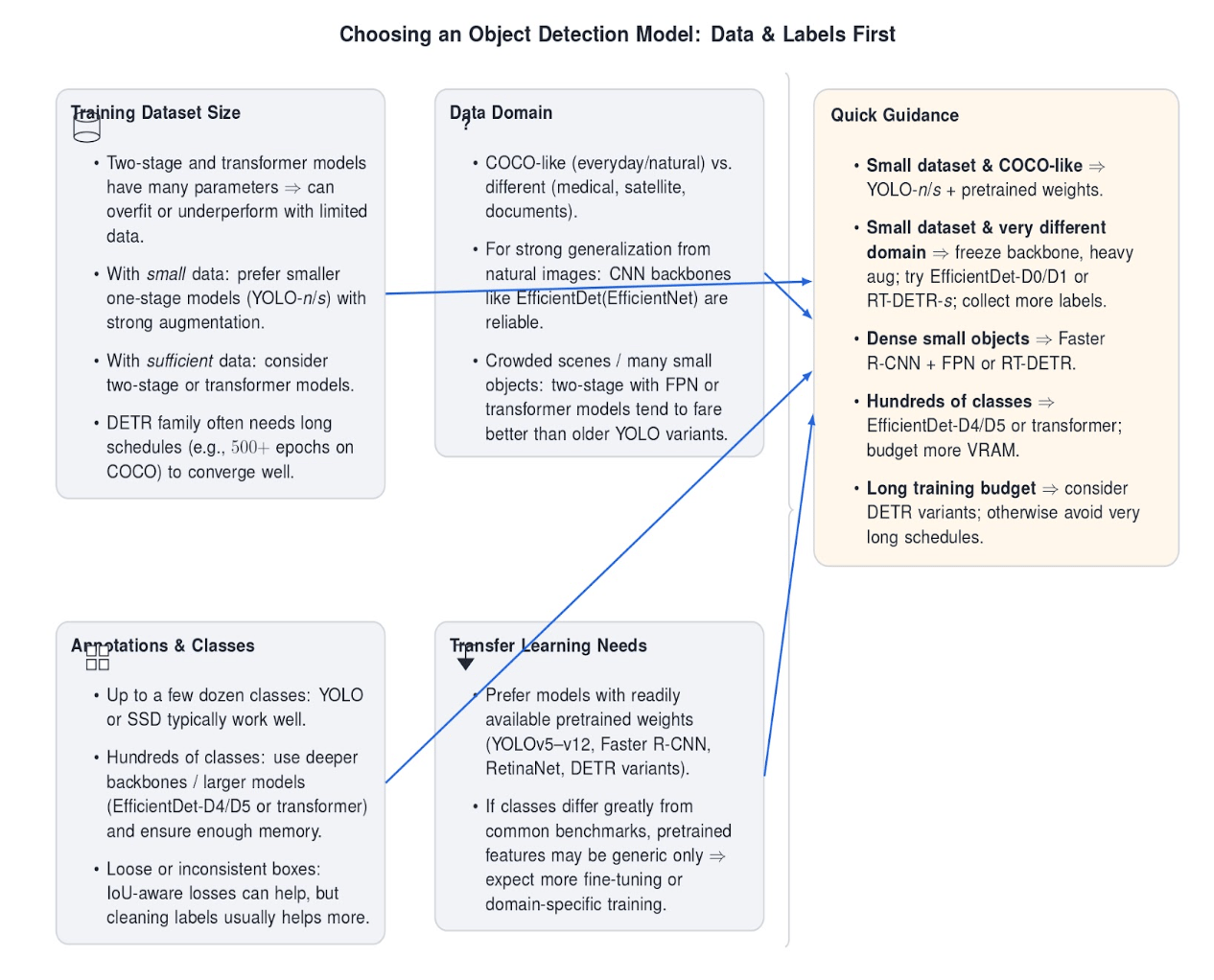
- Training Dataset Size: Some models need more data than others. Two-stage detectors and transformer-based models have many parameters, and can overfit or underperform with limited data. DETR, for instance, was also observed to require very long training schedules (500+ epochs on COCO) to converge well.
- Data Domain: Do you know what kind of images/objects you will be working with? If you are working in a similar domain to COCO (everyday objects, natural images), then most of the “common” models will work fine, and you can use pretrained weights. If your domain is quite different (medical images, satellite imagery, documents, etc), you might prefer models that are known to generalize well. On the other hand, if the objects have very specific textures/shapes, a model with a powerful CNN backbone (like EfficientDet with EfficientNet backbone) might be better at capturing features. It also matters whether objects are generally small/large or dense in images - two-stage detectors with Feature Pyramid Networks or transformer models might fare better on crowded scenes compared to older versions of YOLO.
- Annotations and Classes: How many object classes do you have? How good are your annotation bounding boxes? YOLO and SSD are generally fine with up to a few dozen classes (YOLOv8 was trained on 80 classes of COCO). However, if you have hundreds of classes, you may need a deeper backbone or a larger model with more parameters to avoid hitting capacity limits. You can also choose a model like EfficientDet-D4/D5 or a transformer that can scale up better. Similarly, if your annotation bounding boxes are “loose” or inconsistent, a model that has an IoU-aware loss (some of the newer models incorporate such a loss) might help to handle localization uncertainty. However, annotation consistency can be more easily improved by data cleaning than by advanced loss functions.
- Transfer Learning Needs: If you plan to use transfer learning (most likely), check the availability of pretrained weights. YOLOv5/6/7/8/9/10/11/12, Faster R-CNN, RetinaNet, etc, have pretrained weights on COCO available to download. DETR and its variants also have pretrained models. This will save you a lot of training time and can help with small datasets. However, if your classes are very different from any common benchmark (e.g., industrial components or certain animal species), pretrained weights may be less useful beyond providing general feature extraction. You may need to train or fine-tune more specific models for these use cases.
Deployment Environment (Cloud, Edge Devices, Mobile)
The underlying hardware you intend to run your model on defines the limits of what is possible. The best starting point for choosing is understanding your deployment environment.
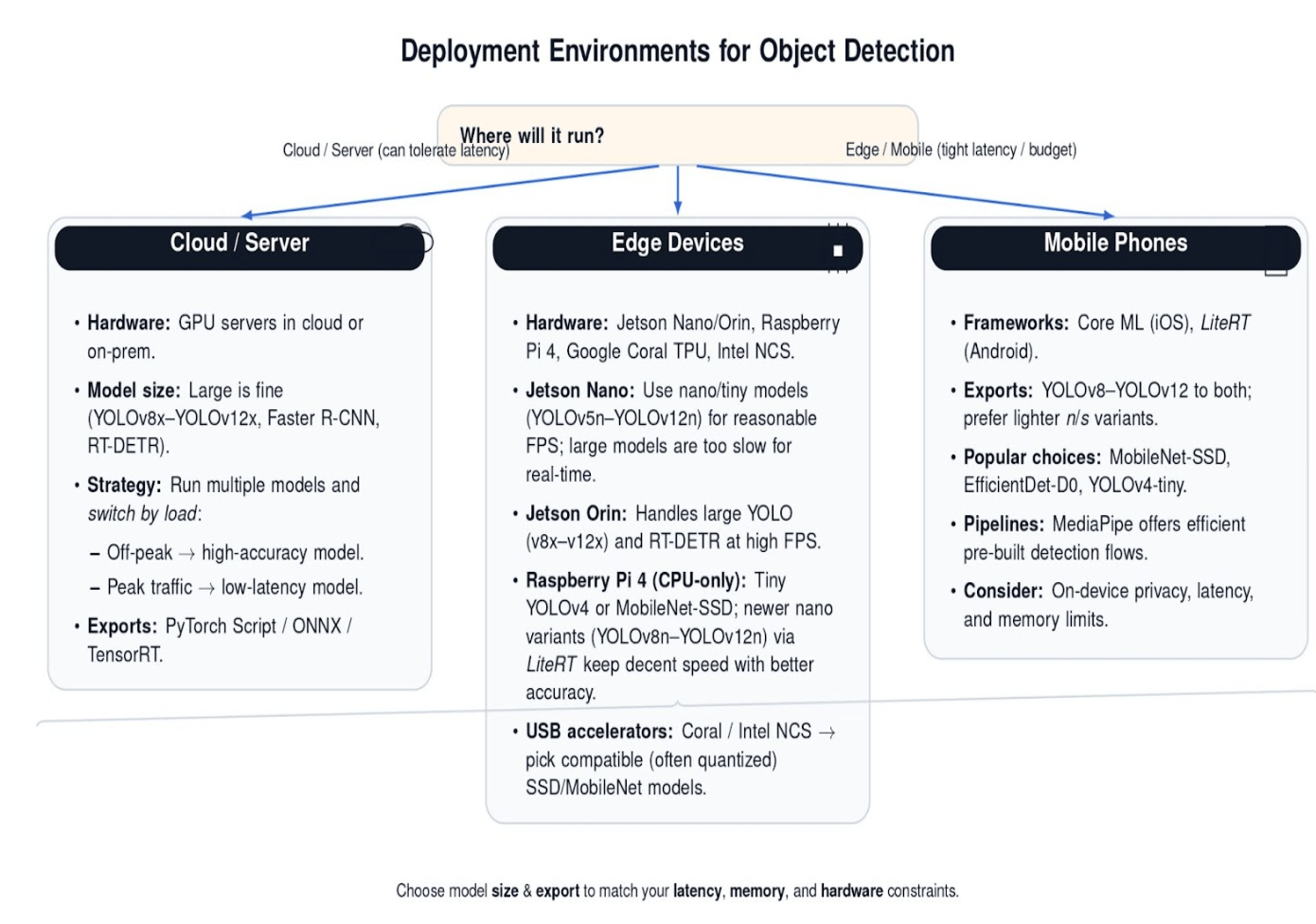
- Cloud / Server Deployment: You can use larger models if you have the option to deploy on a cloud server or a machine with GPUs. In the cloud, you may even deploy multiple models and pick the most appropriate one for the context, e.g., a high-accuracy model during off-peak hours and a low-latency model when requests are heavy.
- Edge Devices: This includes IoT, embedded boards (Jetson series from NVIDIA, Raspberry Pi, Google Coral, etc.), and smartphones. The model must fit the compute and memory constraints of the device. For example:
- On the NVIDIA Jetson Nano, tiny models such as YOLOv5n, YOLOv8n, or more recent YOLOv9n–YOLOv12n can run at a reasonable speed. The larger models are far too slow for real-time use (particularly YOLOv8x or YOLOv12x). On the other hand, Jetson Orin can run these larger models with ease (YOLOv8x through YOLOv12x run smoothly, and even transformer detectors like RT-DETR achieve high FPS).
- On a CPU-only device such as the Raspberry Pi 4, you’re still mostly limited to lightweight networks such as Tiny YOLOv4 or MobileNet-SSD. However, more recent nano variants (such as YOLOv8n through YOLOv12n) can also be exported to LiteRT and deployed on the Pi, often with better accuracy than the older tiny YOLO series while still maintaining reasonable speed. Alternatively, you could offload to a USB accelerator like Coral TPU or Intel NCS; in these cases, choose a compatible model (e.g., Coral only works with certain SSD/MobileNet variants or quantized models).
- Mobile phones: Deployment on iOS/Android will typically leverage a framework like LiteRT or Core ML. Recent YOLO models (YOLOv8 through YOLOv12) can be exported to both formats, allowing them to be used on mobile devices–especially the lighter n and s variants. Traditionally, MobileNet-SSD, EfficientDet-D0, and YOLOv4-tiny have been popular choices for mobile deployment, due to their smaller size and faster inference… If you’re developing a mobile app, you’d naturally gravitate towards those lighter models, or perhaps use frameworks like MediaPipe, which come with pre-built, efficient detection pipelines.
In all the edge cases above, model compression methods will be your friend. Quantization (INT8 quantization can result in major inference speedups on CPUs and some NPUs) and pruning can be used to reduce model sizes. There are many pretrained models that can be quantized with only a minor loss in accuracy.
Comparing Object Detection Models
The following table compares COCO mAP, speed, parameters, and best use cases for the latest YOLO models and other popular detection models. It uses the most recent documented metrics and comparisons from Ultralytics, Roboflow, and other sources as of 2025.
| Model | Architecture Type | COCO mAP (0.5:0.95) | Speed (FPS, GPU) | Params (M) | Key Strengths / Best Use Cases |
|---|---|---|---|---|---|
| YOLOv8 (Large) | One-stage (CNN) | ~52-54% | ~30 FPS (V100 GPU), 60-100+ (TensorRT) | ~68 | Real-time applications, edge and cloud deployment, balanced speed and accuracy |
| YOLOv9 | One-stage (CNN) | ~50-56% | High FPS (~50+) | Varies | Efficient real-time use, slightly improved accuracy over YOLOv8 |
| YOLOv10 | One-stage (CNN) | ~52-56% | Very High (NMS-free training) | Varies | Low latency, production environments, latency-critical apps |
| YOLOv11 | One-stage (CNN) | ~53-56% (+1-2% vs v8) | High FPS (~50+) | Varies | Drop-in upgrade from v8/v9, edge deployment, best accuracy-speed tradeoff |
| YOLOv12 | One-stage (CNN) | Config-dependent, ~48-55% typical | High FPS (TRT/ONNX/TFLite) | Varies | Latest innovations, detection/segmentation/pose, flexible configs |
| Faster R-CNN | Two-stage | ~38-40% | 18-24 FPS (V100 GPU) | ~42 | Max accuracy, offline/batch processing, complex scenes |
| RetinaNet | One-stage | ~35-39% | ~20 FPS | ~34 | Handling imbalanced classes, moderate speed and accuracy |
| SSD MobileNet-V2 | One-stage | ~22-23% | 50+ FPS GPU; ~10 FPS CPU | ~5 | Very low compute, mobile/CPU applications, less accuracy |
| DETR | Transformer | ~42% | ~28 FPS | ~41 | Global context understanding, complex backgrounds |
| Deformable DETR | Transformer | 46-50% | Faster convergence | ~40-50 | Small object detection, faster training |
| DINO (DETR) | Transformer | 50%+ | Moderate | Varies | State-of-the-art accuracy, benchmarks |
| RT-DETR | Real-time Transformer | 52-54% | 100+ FPS (TensorRT/T4) | ~30-60 | Low-latency real-time detection |
| RF-DETR | Real-time Transformer | 58-61% | 25-40 FPS (T4) | ~40-60 | High accuracy near real-time performance |
Notes:
- The YOLO series has seen continuous updates, and newer versions generally offer improvements in accuracy, speed, and efficiency.
- YOLOv10 and later start to introduce new features such as NMS-free training for lower latency inference and architectural improvements for better speed/accuracy trade-offs.
- Transformer-based models (DETR family) offer strong accuracy and complex scene handling, but can come with a higher computational cost.
- SSD MobileNet-V2 is a lightweight model for low-resource scenarios, though with lower accuracy.
- Faster R-CNN is often used when accuracy is prioritized in offline or batch scenarios, but it is generally slower than one-stage detectors.
Best Object Detection Model for Different Use Cases
For some common use-cases, let’s highlight some models that tend to be “best” in their class, keeping in mind that “best” depends on which trade-offs you care about.
Real-time detection
If every frame is critical (surveillance, drones, robotics), start with fast one-stage detectors. YOLOv10 and YOLOv12 offer good speed–accuracy trade-offs, while RF-DETR can achieve real-time on modern edge GPUs using an optimized runtime (TensorRT/INT8). If you want to train from scratch, SSD (particularly MobileNet-SSD) is a lightweight baseline that works well on mobile hardware.
High-accuracy research
For offline settings where latency is less critical (such as medical imaging, benchmarking, and academia), you can choose two-stage detectors (Faster R-CNN) or higher-capacity transformer models (e.g., RF-DETR with stronger backbones). They will require more training and inference time, but often have improved accuracy on small, occluded, or crowded objects, especially at higher input resolutions.
Balanced choice
RetinaNet, YOLOv11-x, YOLOv12, and RT-DETR are reasonably well-rounded options for most production apps. You can choose the variant that fits your latency budget at the desired resolution (640×640, 1280×720, etc.) and export to your deployment format (such as ONNX/TensorRT/TFLite/etc). The models in this tier are appropriate for most mainstream computer vision workloads.
Edge devices & mobile
Running models on embedded CPUs, phone GPUs, or other constrained hardware requires special care: smaller variants and mobile-friendly runtimes. Models like YOLO “n/s” variants (YOLOv8n–YOLOv12n) or MobileNet-SSD can run on these devices with practical throughput. They are best served by LiteRT/Core ML and quantization. If you have an accelerator (such as Jetson and TPU), RF-DETR is a good compromise between accuracy and latency. However, ensure to validate performance on your target device and precision.
How to Choose the Right Model for Your Project
- Define objectives: Objectives can vary widely for various use cases. The most fundamental tradeoff is often speed, accuracy, and model size. For use cases such as real-time video analysis, faster models (YOLOv10, YOLOv12, RF‑DETR Nano) may be prioritized, while research models can often be slower(They may prioritize accuracy over speed).
- Assess hardware: The device you plan to deploy on is another important factor (GPU/CPU/mobile). Based on your available compute, some models may be more suitable than others. For example, MobileNet-SSD and YOLO-Nano can be deployed on a smartphone, whereas RF-DETR Medium or Faster R-CNN will be more accurate on a GPU.
- Evaluate dataset: Small datasets should leverage pre‑trained backbones and simpler models to help prevent overfitting. Large, diverse datasets can train more complex models and may reach better results using transformers.
- Prototype and benchmark: Benchmark a small number of models on your own dataset and test mAP and inference time. Frameworks like Roboflow and Ultralytics make it easy for users to benchmark YOLO, DETR, and more.
- Plan for deployment: Think about integration into the deployment pipeline (ONNX, TensorRT, LiteRT) and other factors such as memory constraints or update cycles. You must choose models that have good support for the frameworks you are using and an active community for easier maintenance.
Frequently Asked Questions
- Which object detection model is best for real‑time applications?
Some models (YOLOv10, YOLOv12, SSD300, and RF‑DETR Nano) have been developed with real‑time performance in mind. They are very fast, with latencies from ~1–5 ms, and also provide high mAP.
- What is the most accurate object detection model in 2025?
Transformer models such as RF‑DETR Medium and RT‑DETR have state‑of‑the‑art accuracy (mAP50 ≈ 73.6 %, mAP50:95 ≈ 54.7) while maintaining low latency. Within the CNNs, YOLOv12 provides high accuracy and efficiency.
- How do I choose between YOLO, Faster R‑CNN, and RetinaNet?
If inference speed is a priority, or you want to deploy to an edge device, then YOLO is usually a good choice. Faster R‑CNN achieves higher precision at the cost of slower inference. RetinaNet is a compromise between accuracy and inference speed. It can be recommended when class imbalance is an issue.
- Can object detection models run on mobile or edge devices?
Yes. There are lightweight models (YOLO‑Nano, MobileNet‑SSD, and RF‑DETR Nano) that can run on mobile GPUs and CPUs. They provide good accuracy while satisfying memory and power constraints.
- What factors affect object detection performance?
Important factors are mAP (accuracy), inference time, model size, dataset characteristics (e.g., object size, class imbalance), and hardware. Consider all these aspects when choosing a model.
Conclusion
Object detection research has evolved from two-stage detectors to highly efficient single‑stage and transformer-based methods. YOLOv12 and RF‑DETR are the new state‑of‑the‑art models with the best performance on image detection tasks, offering a balance of accuracy and speed that was previously unheard of.
Some older models, such as Faster R‑CNN and RetinaNet, remain competitive for certain tasks, especially when accuracy or class imbalance is more critical. The best choice for an object detection model will depend on factors such as accuracy, speed, available hardware, the specific characteristics of your dataset, and the needs of your deployment environment.
Use the model comparison table in this guide as a reference to shortlist candidate models. Prototype and evaluate several models on your own dataset to identify the one that best suits your performance needs. As the field of deep learning research is fast‑moving, stay updated with new releases and evaluate their performance on your task against the baselines you establish.
When you’re ready to deploy—or even run heavy experiments—try DigitalOcean’s Gradient AI GPU Droplets. This is an easy and scalable way to get GPU power without getting tied down by infrastructure overhead. It can help you iterate more quickly and remain agile in a rapidly evolving field.
References and Resources
- Model Comparisons: Choose the Best Object Detection Model for Your Project
- What Is Object Detection? How It Works and Why It Matters
- Best Object Detection Models in 2024
- Performance Benchmark of YOLO v5, v7 and v8
- Faster R-CNN Explained for Object Detection Tasks
- Comparing YOLOv8 and Mask R-CNN for instance segmentation in complex orchard environments
- RT-DETRv2 Beats YOLO? Full Comparison + Tutorial
- RF-DETR: A SOTA Real-Time Object Detection Model
- YOLOv8 vs Faster R-CNN: A Comparative Analysis
- YOLOv8 Performance Benchmarks on NVIDIA Jetson Devices
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
