As AI advances, new demands have emerged for systems to interact with physical environments, interpret sensory input, and make dynamic decisions. While large language models (LLMs) and vision models have made progress in reasoning and perception, they require orchestration with external planners or controllers to perform interactive, goal-directed tasks. Large action models (LAMs) bridge this gap by integrating perception, planning, and control into a unified framework for agents to understand their environment, make decisions, and take physical or digital actions in real time. In this article, we explore why LAMs matter, how they operate, and the role they play across industries.
Key takeaways:
-
LAMs combine multimodal sensory data like vision, touch, and language to understand their environment and perform meaningful, goal-directed actions.
-
From warehouse robotics and surgical automation to game strategy and digital UI interaction, LAMs support agents to operate across physical and digital domains with adaptability and precision.
-
While LLM agents focus on text and reasoning, LAMs extend those capabilities to decision-making, integrating language and neural networks into systems that can plan and act in the real world.
What are large action models?
LAMs are advanced artificial intelligence systems designed to help machines understand their surroundings and take meaningful physical actions in the real world. Unlike language models that focus on generating text or vision models that analyze images, LAMs integrate multiple sensory inputs, like vision, touch, spatial awareness, and language, to guide real-time decision-making and control. These models are trained from large datasets using a combination of techniques like reinforcement learning and copying examples (imitation learning). These models can plan, adapt, and act through a series of steps to get things done.
You can think of LAMs as combining the intelligence of LLMs, the creativity of generative AI, the perception of computer vision systems, and the decision-making abilities of neural networks, prepared for real-world action. For example, imagine a LAM-programmed robot in a kitchen that can understand a spoken command like “make a sandwich.” It would need to detect and identify ingredients using visual input, figure out where everything is, plan a sequence of steps, and use its arms to prepare the sandwich, all without being manually programmed for each step. While this full sequence remains a goal for future systems, models like Google’s RT-2 have demonstrated the ability to recognize objects and perform simple tasks.
Experience the power of AI and machine learning with DigitalOcean Gradient GPU Droplets. Leverage NVIDIA H100, H200, RTX 6000 Ada, L40S, and AMD MI300X GPUs to accelerate your AI/ML workloads, deep learning projects, and high-performance computing tasks with simple, flexible, and cost-effective cloud solutions.
Sign up today to access DigitalOcean Gradient GPU Droplets and scale your AI projects on demand without breaking the bank.
How does a large action model work?
LAMs operate through a sequence of steps that transform raw sensory input into structured, goal-directed actions. This process integrates perception, reasoning, and control through deep learning, planning algorithms, and motor execution systems.
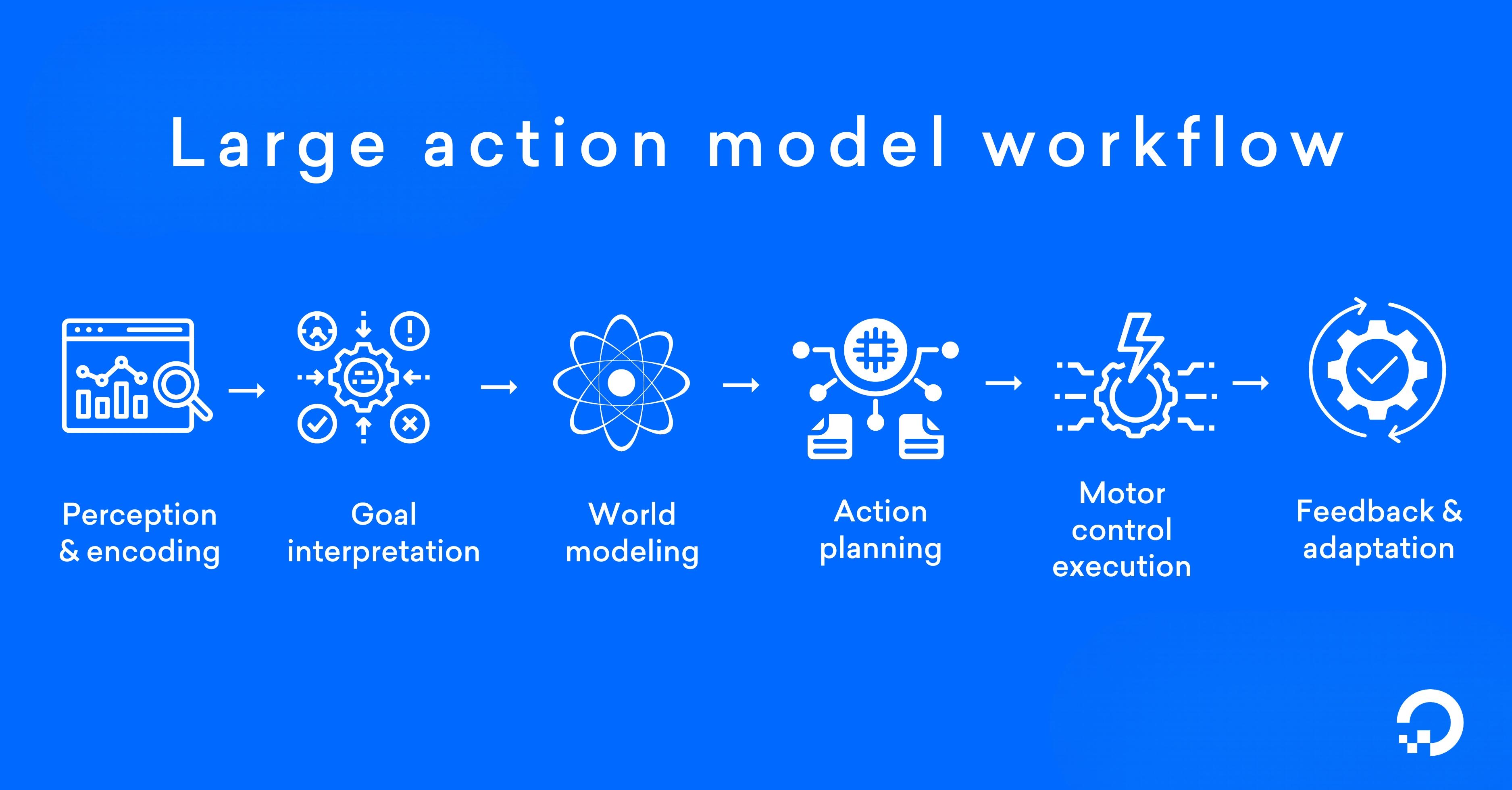
1. Perception and encoding
LAMs begin by processing multimodal inputs such as images, depth maps, tactile feedback, and proprioceptive data. These signals are passed through convolutional neural networks (CNNs) or vision transformers (ViTs) to extract spatial and semantic features. The result is a high-dimensional embedding that captures the current state of the environment.
2. Goal interpretation
The model interprets user-provided commands or task specifications, given in natural language. It uses a language encoder, like a transformer-based model like T5 or BERT, to convert this input into a structured representation that aligns with the model’s action space and internal planning schema and action space.
💡Confused between machine learning and NLP? Discover how machine learning powers decision-making while natural language processing helps machines understand and communicate with humans.
3. World modeling
LAMs construct a predictive representation of the environment using learned world models. These models simulate how the environment will evolve in response to different actions. Techniques like latent dynamics modeling or neural simulators allow the system to forecast future states and estimate the consequences of potential action sequences.
4. Action planning
The model generates a policy or action sequence using planning algorithms such as model-predictive control (MPC), hierarchical reinforcement learning (HRL), or trajectory optimization. This step involves selecting the optimal sequence of discrete or continuous actions based on predicted state transitions and task-specific reward functions.
5. Motor control execution
Low-level control signals are synthesized to execute each step in the action plan. These may include torque values, joint angles, or motion primitives, computed using inverse kinematics, PID controllers, or learned motor policies. The commands are sent to actuators or simulated agents to carry out the task in real-time.
6. Feedback and adaptation
LAMs continuously monitor execution outcomes using real-time sensor data. If deviations from expected states are detected, the model updates its internal state and replans as needed using closed-loop feedback. Adaptive components such as recurrent policies or meta-learned controllers improve resilience and flexibility in unstructured or changing environments like outdoor terrains with variable lighting and weather, or human-robot interaction spaces.
💡Whether you’re a beginner or a seasoned expert, our AI/ML articles help you learn, refine your knowledge, and stay ahead in the field.
Benefits of a large action model
LAMs change how AI systems interact with and reason about the physical world. By integrating perception, planning, and control, they exhibit more adaptive, intelligent, and generalizable behavior in complex real-world scenarios.
1. Greater generalization
LAMs can handle a wide range of tasks across different environments without needing task-specific retraining. Because they are trained on diverse datasets that combine sensory inputs, motor commands, and task instructions, they learn reusable representations that allow them to generalize beyond the training distribution. This makes them highly suitable for dynamic and unstructured settings.
Google DeepMind’s Open X-Embodiment project displays LAMs trained across multiple robot platforms (e.g., robot arms, mobile robots) that generalize to new tasks and hardware configurations with minimal fine-tuning. The model achieves this by using shared action and perception representations across embodiments.
💡Looking for the right approach for building your AI models? Explore the concepts of RAG, fine-tuning, and factors while choosing between RAG vs fine-tuning.
2. Real-world adaptability
LAMs integrate sensory feedback (e.g., vision, proprioception, tactile data) with adaptive control strategies, making them resilient to uncertainty, sensor noise, or physical disturbances. Their ability to replan and adapt in real time improves their calculations in complex, real-world deployments.
In a study by Miki et al. (2022), researchers trained a quadrupedal robot to walk autonomously in outdoor environments like snow-covered trails, rocky slopes, and foggy terrain. The system fused vision and proprioceptive inputs using an attention-based recurrent encoder to adapt its gait in real time.
3. Improved sample efficiency
LAMs simulate environments internally, which reduces the need for large numbers of real-world trial-and-error episodes. Through learned world models and latent dynamics, they can “imagine” multiple outcomes before acting, leading to more efficient policy learning and fewer physical interactions required.
The DreamerV3 agent uses latent world models and planning (similar to LAMs) to achieve sample-efficient learning in both simulated and real-robot environments. It outperforms model-free methods using far fewer environment steps.
💡 Build your own AI assistant from scratch! Learn how to create and deploy a terminal-based ChatGPT bot using Python and OpenAI APIs.
4. Multimodal integration
LAMs combine various data types, such as visual, spatial, linguistic, and haptic, into a unified decision-making pipeline. This allows them to understand complex instructions and contextual cues while mapping them to precise physical actions.
The PaLM-E-562B model with 562B parameters combines language, vision, and embodied reasoning to allow robots to follow natural language commands, recognize objects, and perform routine tasks.
💡Explore Multimodal Large Diffusion Language Models (MMaDA), a diffusion-based model that blends text and image understanding, now runnable on DigitalOcean GPU Droplets for faster, cost-effective AI generation.
Confused between NLP and NLU? Read this article to understand how they differ and work together to make AI conversations more human-like.
Difference between LAM vs LLM agents
While both LAMs and LLMs agents are built on deep learning architectures and use transformer-based models, their goals, inputs, and outputs are fundamentally different. LLM agents operate in the domain of language and symbolic reasoning, whereas LAMs extend these capabilities into physical interaction and real-world decision-making.
| Feature | LAM | LLM agent |
|---|---|---|
| Core function | Executes physical actions in real-world or simulated environments | Processes and generates text-based responses or reasoning |
| Input types | Multimodal ( vision, proprioception, tactile, language) | Text (natural language prompts, structured inputs) |
| Output types | Action policies, motor commands, trajectory plans | Text responses, API calls, and task decomposition |
| Components | Perception module, world model, action planner, control system | Language encoder, memory module, and tool-calling capabilities |
| Use cases | Robotics, autonomous navigation, and embodied AI agents | Chatbots, coding assistants, and knowledge retrieval agents |
| Real-time feedback | Responds to continuous, low-level sensor feedback from the environment (e.g., vision, proprioception) | Responds to discrete feedback from tools, APIs, or user inputs during a multi-turn interaction |
| Training data | Behavior datasets, sensory logs, and action sequences | Text corpora (e.g., books, web data, code repositories) |
| Example model | RT-2, PaLM-E, Open X-Embodiment | GPT-4, Claude, Gemini, Code Llama |
💡You can now build an AI agent or chatbot in six steps using the DigitalOcean Gradient platform
Challenges of large action models
Despite their growing potential, LAMs face challenges when bridging high-level intelligence with real-world physical actions. These challenges arise from the complexity of environments and the computational demands of integrating perception, reasoning, and control into a single architecture.
1. Real-world grounding
LAMs must accurately interpret raw sensory data (e.g., vision, depth, touch) and map it to meaningful representations of the environment. This grounding is difficult in unstructured or cluttered settings where objects may be partially visible, occluded, or constantly moving. Small errors in perception can lead to cascading failures in downstream planning and control.
2. High data requirements
LAMs need vast and diverse multimodal datasets that pair sensory inputs with physical actions across different contexts. Gathering such data in real environments is time-consuming, expensive, and error-prone. Simulated data can help, but lacks the richness and unpredictability of the real world.
3. Safety and control precision
Executing physical actions requires precise control over actuators. A small mistake in torque or joint angle can cause hardware damage or safety risks in collaborative human-robot environments. Unlike LLMs, LAMs must adhere to real-world physical constraints, including friction, force limits, and reaction time.
4. Generalization under dynamics
LAMs must adapt to changes in the environment over time, like lighting, object positions, or user behavior, without constant retraining. Generalization becomes more difficult when environments introduce nonlinear dynamics or unexpected perturbations.
Large action model use cases
LAMs are effective in high-stakes contexts involving task decomposition, real-world interactivity, and decision-making.
1. Autonomous robotics
LAMs help robots move beyond reactive behavior by planning extended sequences of actions. In warehouse logistics, for instance, a robot can be prompted to “pick and pack all items for order #1245,” and the LAM will translate that into a structured series of steps involving object identification, path planning, manipulation, and coordination with other robots. Unlike traditional robotic systems that rely on rigidly pre-programmed instructions, LAMs adapt in real-time to environmental changes.
Covariant, an AI robotics company, uses LAM-like architectures to build robotic arms that perform warehouse pick-and-pack operations. Their system combines vision, planning, and control modules to execute long-horizon tasks. Covariant’s “Foundations Model for Robotics” is trained on millions of real-world actions to generalize across different object types and workflows.
2. Game-playing agents
In game development and open-world simulations, LAMs support agents in making long-term decisions with branching possibilities. Instead of selecting the next move based solely on immediate reward, the model can plan a series of actions such as resource gathering, unit training, and strategic positioning, aligned to high-level goals like “dominate territory” or “build a trade empire.” This mimics human-like reasoning and planning.
DeepMind’s AlphaStar used LAM-like structures to compete in StarCraft II, planning actions across multiple time horizons. More recently, OpenAI Five, while not strictly called an LAM, shares a similar architecture for implementing a high-level strategy in Dota 2. The agent learned to manage long action sequences involving team coordination, map control, and item optimization.
💡Choosing the right game hosting provider can free up your developers, cut costs, and help you focus on building great gaming experiences.
3. User interface automation
LAMs are not limited to controlling physical robots; they can also perform complex tasks in digital environments by perceiving screen elements, planning action sequences, and executing them in real time. Unlike traditional automation scripts, LAMs adapt to changing UI layouts and can handle multimodal instructions.
Rabbit’s LAM Playground has an agent that takes visual snapshots of a webpage, interprets elements like buttons and text fields, and performs user-guided actions like booking tickets, filling forms, or managing apps. These actions are executed live through the Rabbithole browser interface, applying real-time perception-action loops in a digital setting.
4. Robotics-assisted surgery
In healthcare, surgical robots guided by LAMs can assist with complex procedures by following a multi-step surgical plan generated from high-level instructions. For example, “perform laparoscopic appendectomy” involves dozens of coordinated actions like incision, camera navigation, dissection, and suturing. LAMs allow for fine-grained control while maintaining contextual awareness of the surgical workflow. While promising, LAMs in surgical robotics are still in the experimental phase. Clinical deployment requires extensive validation, regulatory approvals, and oversight to ensure patient safety and ethical compliance.
Researchers at Johns Hopkins developed an autonomous surgical robot that performed soft-tissue surgery using a vision-planning-action loop akin to LAMs. The Smart Tissue Autonomous Robot (STAR) executed tasks like suturing with higher precision than human surgeons.
5. Scientific research automation
LAMs are being applied in laboratory automation to plan and carry out experimental procedures. Given a goal like “synthesize a new material with desired conductivity,” a LAM can design experiments, control robotic lab equipment, adjust parameters based on observations, and refine hypotheses.
ORGANA is a robotic assistant that interacts with chemists, controls lab devices, and performs multi-step experiments such as solubility tests, pH measurement, and electrochemistry. It uses vision-guided planning and real-time feedback to sequence complex protocols (19 steps in one test), adapting to experimental data.
References
Large action models FAQ
Can I build and train a large action model on my own infrastructure?
Yes, but it requires GPU resources, high-throughput data pipelines, and robotics or simulation environments. Using cloud GPU infrastructure like DigitalOcean GPU Droplets can help you scale without upfront hardware investment.
How are LAMs tested before being deployed in the real world?
LAMs are usually tested in high-fidelity simulation environments that mimic real-world physics and visuals. These simulations help validate perception and action planning without risking hardware or safety.
Are LAMs only useful for robotics?
Not at all. While robotics is an important application, LAMs are also used in digital domains like UI automation, scientific research, and strategy games, anywhere agents need to plan and act based on sensory input and goals.
Accelerate your AI projects with DigitalOcean Gradient GPU Droplets
Accelerate your AI/ML, deep learning, high-performance computing, and data analytics tasks with DigitalOcean Gradient GPU Droplets. Scale on demand, manage costs, and deliver actionable insights with ease. Zero to GPU in just 2 clicks with simple, powerful virtual machines designed for developers, startups, and innovators who need high-performance computing without complexity.
Key features:
-
Powered by NVIDIA H100, H200, RTX 6000 Ada, L40S, and AMD MI300X GPUs
-
Save up to 75% vs. hyperscalers for the same on-demand GPUs
-
Flexible configurations from single-GPU to 8-GPU setups
-
Pre-installed Python and Deep Learning software packages
-
High-performance local boot and scratch disks included
-
HIPAA-eligible and SOC 2 compliant with enterprise-grade SLAs
Sign up today and unlock the possibilities of DigitalOcean Gradient GPU Droplets. For custom solutions, larger GPU allocations, or reserved instances, contact our sales team to learn how DigitalOcean can power your most demanding AI/ML workloads.
About the author
Sujatha R is a Technical Writer at DigitalOcean. She has over 10+ years of experience creating clear and engaging technical documentation, specializing in cloud computing, artificial intelligence, and machine learning. ✍️ She combines her technical expertise with a passion for technology that helps developers and tech enthusiasts uncover the cloud’s complexity.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
