AI Technical Writer

Machine learning models can work with numbers but not with text. Most real-world datasets consist of categorical features such as color, country, or type of specific products. Converting these non-numerical features to numerical representations before feeding this data to the model becomes a challenge. This is where One-Hot Encoding comes in. It is a simple yet powerful technique that turns categorical data into a numerical format that can easily be fed to the model. Think of it as teaching a model that “Red,” “Green,” and “Blue” are different but not ordered like 1 < 2 < 3.
Key Takeaways
- One-hot encoding converts categorical variables into binary vectors, making them suitable for machine learning models.
- Prevents ordinal misinterpretation, ensures each category is treated as independent and equal.
- Use label encoding only when categories have a natural order.
- For large datasets, apply optimizations like sparse matrices, drop=‘first’, and dimensionality reduction.
- Efficient handling of encoded data ensures faster training, reduced memory consumption, and better model performance.
What is One-Hot Encoding?
One-Hot Encoding transforms categorical values into binary vectors. Each category becomes a separate column, with 1 indicating the presence of that category and 0 representing its absence.
Example:
| Color | Red | Green | Blue |
|---|---|---|---|
| Red | 1 | 0 | 0 |
| Green | 0 | 1 | 0 |
| Blue | 0 | 0 | 1 |
This way, the model treats each category independently and doesn’t assume any relationship between them.
Original Dataset:
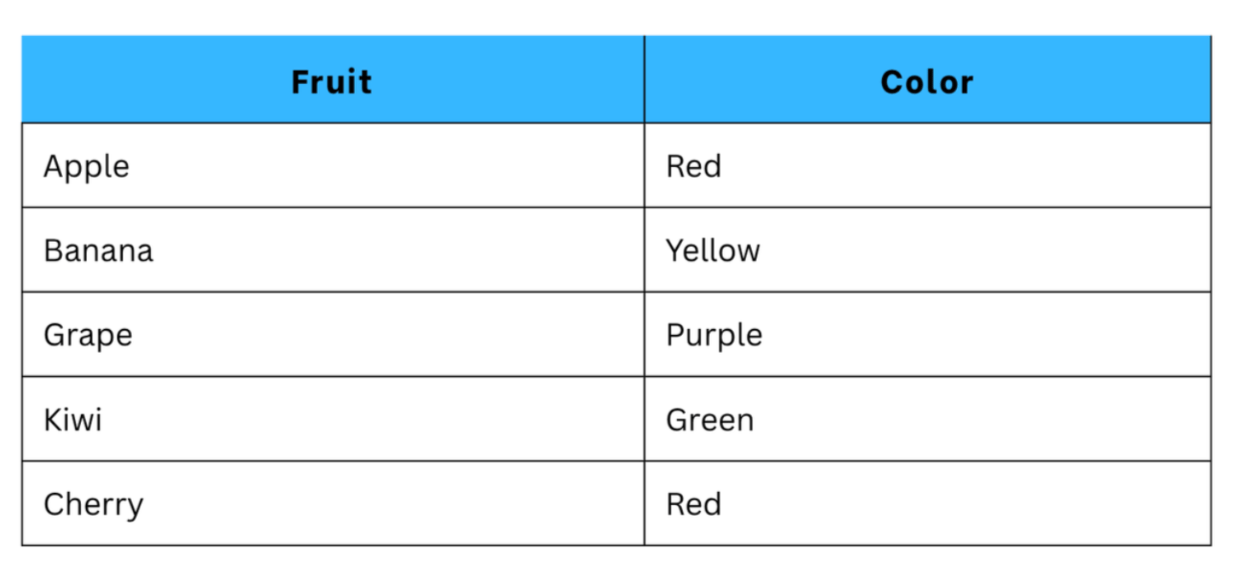
After One-hot Encoding:
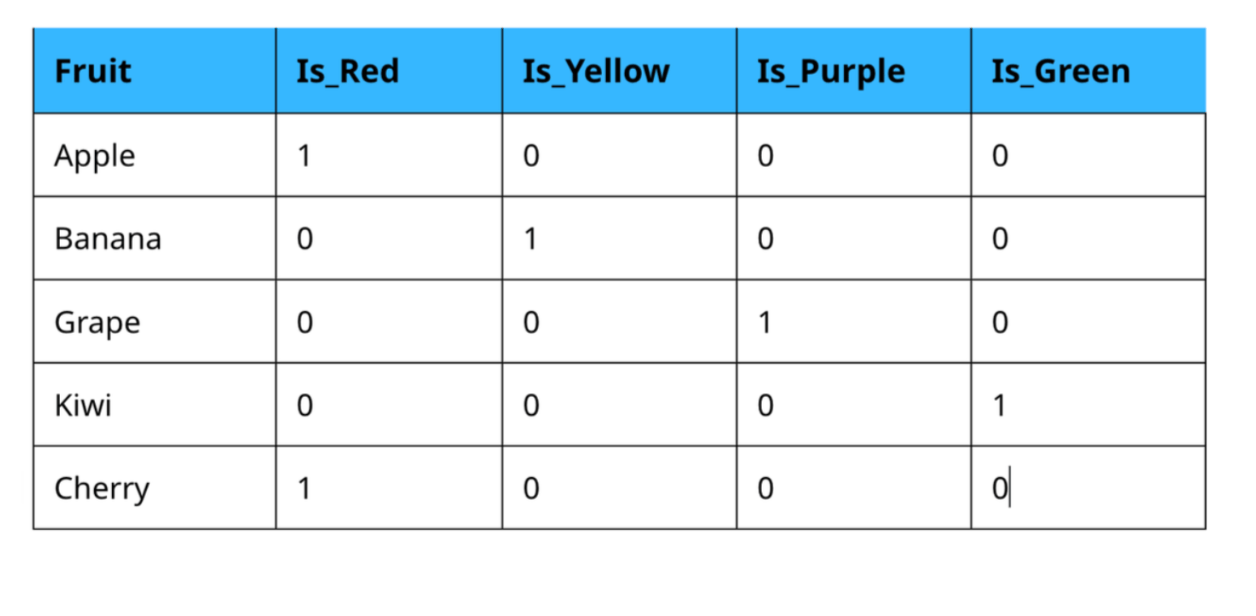
Why Use One-Hot Encoding?
As we already understood, a machine learning model can only take numerical values as input; hence, one-hot encoding is a simple yet powerful method to convert these values to numerical values, which we can easily feed to our model. Another reason to use this approach is that One-hot encoding ensures categorical data can easily be integrated into models like linear regression, logistic regression, decision trees, and neural networks without distortions caused by numeric misinterpretation. Almost every data preprocessing library, such as Pandas, Scikit-learn, and TensorFlow, provides built-in methods for one-hot encoding. It’s a standard practice in any ML pipeline and forms the foundation for more advanced encoding methods like embeddings. Another way to convert these values is to use numerical labels, for instance: Red = 1, Green = 2, Blue = 3, This process is called Label Encoding.
What is Label Encoding?
Label encoding is the process of converting categorical features into numerical features(i.e 0, 1, 2, 3, etc). Label encoding involves converting each value in a column to a number. Let’s look at an example and understand it further:
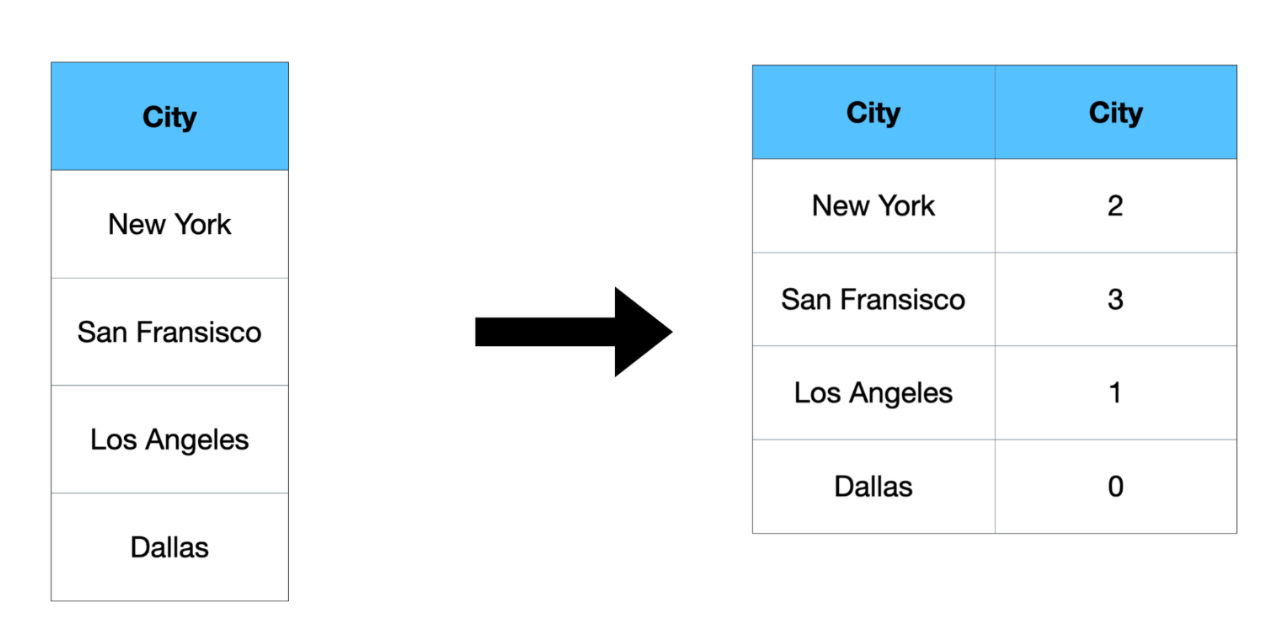
Here, different numbers are assigned to different city names, unlike a separate column for each city as we did in One-hot Encoding.
Techniques such as label encoding can help reduce the number of labels, but they introduce a serious problem: the model will interpret these numbers as having an inherent order or distance. It might assume New York (2) lies between Los Angeles (1) and San Francisco (3), which doesn’t make any logical sense for a categorical feature.
This is where One-Hot Encoding becomes essential. By converting each category into a separate column with binary values (1 or 0), one-hot encoding ensures there’s no implied ranking or hierarchy between categories.
| Color | Red | Green | Blue |
|---|---|---|---|
| Red | 1 | 0 | 0 |
| Green | 0 | 1 | 0 |
| Blue | 0 | 0 | 1 |
Here, all colors are treated as equally distinct, eliminating any false assumption of “greater than” or “less than.” If you encode colors as numbers:
Red = 1, Green = 2, Blue = 3
The model might think Blue > Green > Red. But with one-hot encoding:
Red = [1,0,0], Green = [0,1,0], Blue = [0,0,1]
The model understands each color as a separate, independent entity, exactly what we want.
When your categorical variable has a natural order or ranking, using Label Encoding is more appropriate. Label Encoding assigns each category a unique integer value, preserving the inherent order between them. For example, consider the feature “Size” with categories: Small, Medium, Large. Here, these categories have a meaningful order: Small < Medium < Large. Using One-Hot Encoding would ignore this relationship, while Label Encoding captures it effectively.
| Size | Label Encoded |
|---|---|
| Small | 0 |
| Medium | 1 |
| Large | 2 |
In this case, Label Encoding tells the model that “Large” is greater than “Medium,” which makes logical sense.
However, Label Encoding should be used only for ordinal features and not for nominal categories like color or country where no inherent order exists. Using it in those cases can mislead the model into interpreting false numerical relationships.
One-Hot Encoding vs Label Encoding
| Aspect | One-Hot Encoding | Label Encoding |
|---|---|---|
| Representation | Creates a binary vector for each category | Assigns an integer label to each category |
| Ordinal Relationship | None: treats all categories as distinct and unordered | Preserves the natural order among categories |
| Number of Features Created | Increases with the number of unique categories | Always one feature per column |
| Best For | Nominal (unordered) categorical data like color, city, brand | Ordinal (ordered) categorical data like size, rating, and education level |
| Model Interpretation | Easier to interpret since categories remain independent | Can mislead models if used on non-ordinal data |
| Memory Usage | Higher since it creates multiple columns | Lower, as there is only one column per feature |
| Example (Colors) | Red → [1,0,0], Green → [0,1,0], Blue → [0,0,1] | Red → 0, Green → 1, Blue → 2 |
| Supported By | All ML frameworks (Pandas, Scikit-learn, TensorFlow) | All ML frameworks (Pandas, Scikit-learn, TensorFlow) |
How to Perform One-Hot Encoding (with Python Examples)
Let’s see how to apply one-hot encoding in Python.
Using Pandas:
import pandas as pd
data = {'Color': ['Red', 'Green', 'Blue', 'Green']}
df = pd.DataFrame(data)
encoded_df = pd.get_dummies(df, columns=['Color'])
print(encoded_df)
Output:
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 1 0
Using Scikit-learn:
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
data = pd.DataFrame({'Color': ['Red', 'Green', 'Blue']})
encoder = OneHotEncoder(sparse=False)
encoded = encoder.fit_transform(data[['Color']])
print(encoded)
Output:
[[0. 0. 1.]
[0. 1. 0.]
[1. 0. 0.]]
To get back the column names:
print(encoder.get_feature_names_out(['Color']))
When Not to Use One-Hot Encoding
One-hot encoding works great for low-cardinality categorical data (few unique categories). However, if a column has hundreds or thousands of unique values, encoding it will create a huge number of columns, causing dimensionality explosion, also known as the curse of dimensionality.
In such cases, use alternatives like:
- Label Encoding for ordinal categories.
- Target Encoding for categorical predictors.
- Embedding layers in deep learning models.
Handling One-Hot Encoded Data Efficiently
While one-hot encoding is a powerful technique for representing categorical variables, it can lead to high-dimensional feature spaces, especially if datasets contain many unique categories (high cardinality). This issue, often called the “curse of dimensionality,” can make models slower, increase memory usage, and even lead to overfitting.
Here are a few practical techniques to handle one-hot encoded data more efficiently:
1. Use Sparse Matrices
When you apply one-hot encoding, most of the generated values are zeros (since only one position in each vector is “hot” or set to 1). Instead of storing all those zeros explicitly, you can use a sparse matrix representation to store only the positions of the non-zero elements. In scikit-learn, you can enable this optimization by setting:
encoder = OneHotEncoder(drop='first', sparse=True)
Just this one step can drastically reduce memory usage and speed up computation for large datasets.
2. Drop the First Column to Prevent Multicollinearity
In cases where categories are mutually exclusive, one of the columns can be dropped without losing information. For instance, if you have three colors — Red, Green, Blue — knowing two is enough to infer the third. By using:
OneHotEncoder(drop='first')
You reduce redundancy and prevent multicollinearity, which can interfere with linear models such as Linear Regression or Logistic Regression.
3. Combine with Dimensionality Reduction Techniques
When the number of features explodes due to many categorical variables, apply dimensionality reduction to compress the feature space while retaining most of the variance.
Techniques like Principal Component Analysis (PCA) or Autoencoders are commonly used:
- PCA transforms correlated features into a smaller set of uncorrelated components.
- Autoencoders (neural network-based) learn efficient lower-dimensional representations automatically.
Combining these with one-hot encoding ensures that your models remain computationally efficient without sacrificing predictive performance.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('encoder', OneHotEncoder(sparse=True, drop='first')),
('reduce_dim', PCA(n_components=10))
])
Practical Example: One-Hot Encoding in a Classification Model
Let’s apply it to a simple model predicting fruit type:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import OneHotEncoder
data = pd.DataFrame({
'Fruit': ['Apple', 'Banana', 'Mango', 'Banana', 'Apple'],
'Weight': [150, 120, 200, 130, 160],
'Label': [1, 0, 1, 0, 1]
})
X = data[['Fruit', 'Weight']]
y = data['Label']
encoder = OneHotEncoder(drop='first', sparse=False)
encoded = encoder.fit_transform(X[['Fruit']])
import numpy as np
X_final = np.concatenate([encoded, X[['Weight']].values], axis=1)
model = LogisticRegression()
model.fit(X_final, y)
print("Model trained successfully!")
FAQ’s
1. What is the main purpose of one-hot encoding?
One-hot encoding converts categorical variables into a binary matrix so that machine learning models can interpret them numerically without implying any ordinal relationship. This ensures each category is treated as distinct and independent.
2. When should I use label encoding instead of one-hot encoding?
Use label encoding when your categorical variable has a natural order (e.g., “Low,” “Medium,” “High”). It assigns integer values to categories, preserving their rank. However, for non-ordinal categories (like colors or city names), one-hot encoding is the better choice to prevent false order assumptions.
3. Why does one-hot encoding cause high dimensionality?
Each unique category generates a new binary column. For datasets with hundreds or thousands of unique values, this creates a massive feature space, leading to memory inefficiency and slower training. Sparse matrices and dimensionality reduction help mitigate this.
4. Can one-hot encoding be used for text data?
Not directly. One-hot encoding is ideal for structured categorical data. For textual data, techniques like Bag of Words, TF-IDF, or word embeddings (Word2Vec, BERT) are more effective since they capture semantic relationships.
5. How can I prevent multicollinearity in one-hot encoded features?
You can use the drop='first' parameter in OneHotEncoder to remove one column per feature. This avoids redundancy without losing information and is especially useful for linear models.
6. Does one-hot encoding affect model performance?
It depends on the dataset and model. While it improves interpretability for categorical data, it can slow down training if not optimized. Tree-based models (like XGBoost or Random Forests) can sometimes handle categorical data directly, reducing the need for full one-hot encoding.
Conclusion
In this article, we understood how a simple yet powerful technique can transform your categorical data into a format that can easily be fed to your machine learning model. One-hot encoding eliminates the issue of assigning arbitrary numerical values that could mislead algorithms by converting categories into binary vectors. However, we also learned that while it enhances interpretability and model accuracy, it can also lead to high-dimensional data, especially with features containing many unique categories.
To handle this efficiently, techniques such as using sparse matrices, dropping redundant columns, or applying dimensionality reduction methods like PCA can be valuable. Understanding when and how to use one-hot encoding, along with its limitations, thus allows data practitioners to create cleaner, more efficient datasets and build models that generalize better.
Mastering these simple yet effective techniques is a foundational step toward preparing high-quality data, which directly impacts the success of any machine learning project.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
