
Introduction
Once your application is up and running in a cloud server environment, you may be wondering how you can improve your server environment to make the leap from “it works” to a full-fledged production environment. This article will help you get started with planning and implementing a production environment by creating a loose definition of “production”, in the context of a web application in a cloud server environment, and by showing you some components that you can add to your existing architecture to make the transition.
For the purposes of this demonstration, let’s assume that we’re starting with a setup similar to one described in 5 Common Server Setups, like this two-server environment that simply serves a web application:
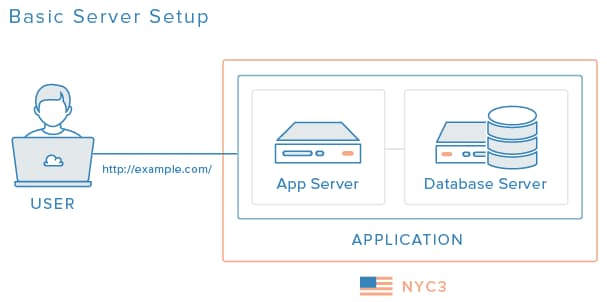
Your actual setup might be simpler or more complex, but the general ideas and components discussed herein should apply to any server environment to a some extent.
Let’s get started with defining what we mean when we say “production environment”.
What is a Production Environment?
A server environment for a web application, in a general sense, consists of the hardware, software, data, operational plans, and personnel that are necessary to keep the application working. A production environment typically refers to a server environment that was designed and implemented with utmost consideration for acceptable levels of these factors:
- Availability: The ability for the application to be usable by its intended users during advertised hours. Availability can be disrupted by any failure that affects a critical component severely enough (e.g. the application crashes due to a bug, the database storage device fails, or the system administrator accidentally powers off the application server).
One way to promote availability is to decrease the number of single points of failure in an environment. For example, using a static IP and a monitoring failover service ensures that users only access healthy load balancers.To learn more, read this section of How To Use Reserved IPs and this article on load balancing.
-
Recoverability: The ability to recover an application environment in the event of system failure or data loss. If a critical component fails, and is not recoverable, availability will become non-existent. Improving maintainability, a related concept, reduces the time needed to perform a given recovery process in the event of a failure, and therefore can improve availability in the event of a failure
-
Performance: The application performs as expected under average or peak load (e.g. it is reasonably responsive). While very important to your users, performance only matters if the application is available
Take some time to define acceptable levels for each of the items just mentioned, in the context of your application. This will vary depending on the importance and nature of the application in question. For example, it is probably acceptable for a personal blog that serves few visitors to suffer from occasional downtime or poor performance, as long as the blog can be recovered, but a company’s online store should strive very high marks across the board. Of course, it would be nice to achieve 100% in every category, for every application, but that is often not feasible due to time and money constraints.
Note that we have not mentioned (a) hardware reliability, the probability that a given hardware component will function properly for a specified amount of time before failure, or (b) security as factors. This is because we are assuming (a) the cloud servers you are using are generally reliable but have the potential for failure (as they run on physical servers), and (b) you are following security best practices to the best of your abilities—simply put, they are outside of the scope of this article. You should be aware, however, that reliability and security are factors that can directly affect availability, and both can contribute the need for recoverability.
Instead of showing you a step-by-step procedure for creating a production environment, which is impossible due the varying needs and nature of every application, we will present some tangible components that can utilize to transform your existing setup into a production environment.
Let’s take a look at the components!
1. Backup System
A backup system will grant you with the ability to create periodic backups of your data, and restore data from backups. Backups also allow for rollbacks in your data, to a previous state, in the event of accidental deletion or undesired modification, which can occur due to a variety of reasons including human error. All computer hardware has a chance of failure at some point in time, which can potentially cause data loss. With this in mind, you should maintain recent backups of all your important data.
Required for Production? Yes. A backup system can mitigate the effects of data loss, which is necessary to achieve recoverability and, therefore, aids availability in the event of data loss—but it must be used in conjunction with solid recovery plans, which are discussed in the next section. Note that DigitalOcean’s snapshot-based backups may not be sufficient for all of your backup needs, as it is not well-suited for making backups of active databases and other applications with high disk write I/O—if you run these types of applications, or want more backup scheduling flexibility, be sure to use another backup system such as Bacula.
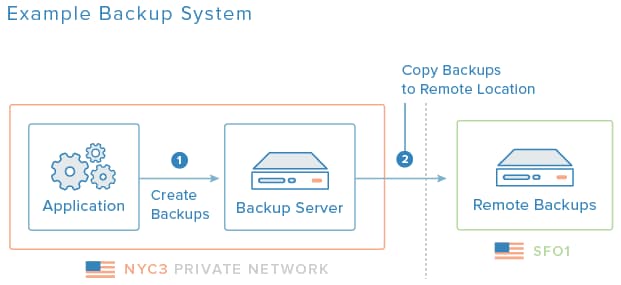
The diagram above is an example of a basic backup system. The backup server resides in the same data center as the application servers, where the initial backups are created. Later, off-site copies of the backups are made to a server in a different data center to ensure the data is preserved in the case of, say, a natural disaster.
Considerations
- Backup Selection: The data that you will back up. Minimally, back up any data that you can’t reliably reproduce from an alternative source
- Backup Schedule: When and how frequently you will perform full or incremental backups. Special considerations must be taken for backups of certain types of data, such as active databases, which can affect your backup schedule
- Data Retention Period: How long you will keep your backups before deleting them
- Disk Space for Backups: The combination of three previous items affects the amount of disk space your backup system will require. Take advantage of compression and incremental backups to decrease the disk space required by your backups
- Off-site Backups: To protect your backups against local disasters, within a particular datacenter, it is advisable to maintain a copy of your backups in a geographically separate location. In the diagram above, the backups of NYC3 are copied to SFO1 for this purpose
- Backup Restoration Tests: Periodically test your backup restoration process to make sure that your backups work properly
Related Tutorials
2. Recovery Plans
Recovery plans are a set of documented procedures to recover from potential failures or administration errors within your production environment. At minimum, you will want a recovery plan for each crippling scenario that you deem will inevitably occur, such as server hardware failure or accidental data deletion. For example, a very basic recovery plan for a server failure could consist of a list of the steps that you took to perform your initial server deployment, with extra procedures for restoring application data from backups. A better recovery plan might, in addition to good documentation, leverage deployment scripts and configuration management tools, such as Ansible, Chef, or Puppet, to help automate and quicken the recovery process.
Required for Production? Yes. Although recovery plans don’t exist as software in your server environment, they are a necessary component for a production setup. They enable you to utilize your backups effectively, and provide a blueprint for rebuilding your environment or rolling back to a desired state when the need arises.
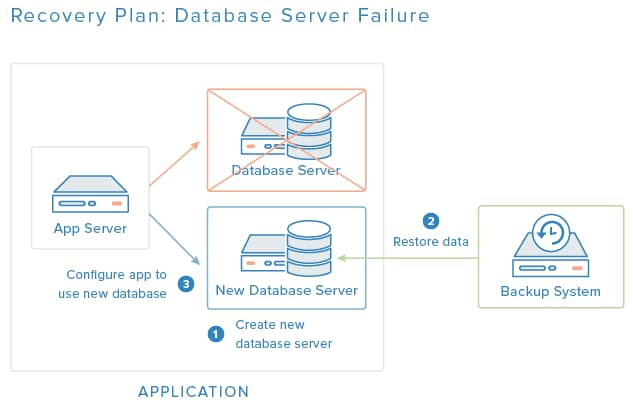
The diagram above is an overview of a recovery plan for a failed database server. In this case, the database server will be replaced by a new one with the same software installed, and the last good backup will be used to restore the server configuration and data. Lastly, the app server will be configured to use the new database server.
Considerations
- Procedure Documentation: The set of documents that should be followed in a failure event. A good starting point is building a step-by-step document that you can follow to rebuild a failed server, then adding steps for restoring the various application data and configuration from backups
- Automation Tools: Scripts and configuration management software provide automation, which can improve deployment and recovery processes. While step-by-step guides are often adequate for simply recovering from a failure, they must be executed by a person and therefore are not as fast or consistent as an automated process
- Critical Components: The components that are necessary for your application to function properly. In the example above, both the application and database servers are critical components because if either fails, the application will become unavailable
- Single Points of Failure: Critical components that do not have an automatic failover mechanism are considered to be a single point of failure. You should attempt to eliminate single points of failure, to the best of your ability, to improve availability
- Revisions: Update your documentation as your deployment and recovery process improves
3. Load Balancing
Load balancing can be added to a server environment to improve performance and availability by distributing the workload across multiple servers. If one of the servers that is load balanced fails, the other servers will handle the incoming traffic until the failed server becomes healthy again. In a cloud server environment, load balancing typically can be implemented by adding a load balancer server, that runs load balancer (reverse proxy) software, in front of multiple servers that run a particular component of an application.
Required for Production? Not necessarily. Load balancing is not always required for a production environment but it can be an effective way to reduce the number of single points of failure in a system, if implemented correctly. It can also improve performance by adding more capacity through horizontal scaling.
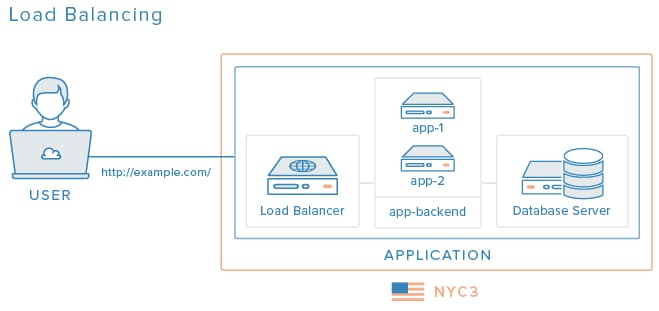
The diagram above adds an additional app server to share the load, and a load balancer to spread user requests across both app servers. This setup can help with performance, if the single app server was struggling to keep up with the traffic, and it can also help keep the application available if one of the application servers fails. However, it still has two single points of failure in the database server and the load balancer server itself.
Note: DigitalOcean Load Balancers are a fully-managed, highly available load balancing service. If you are running your application on DigitalOcean, the Load Balancer service may a good fit for your environment.
Considerations
- Load Balanceable Components: Not all components in an environment can be load balanced easily. Special consideration must be made for certain types of software such as databases or stateful applications
- Application Data Replication: If a load balanced application server stores application data locally, such as uploaded files, this data must be made available to the other application servers via methods such as replication or shared file systems. This is necessary to ensure that the application data will be available no matter which application server is chosen to serve a user request
- Performance Bottlenecks: If a load balancer does not have enough resources or is not configured properly, it can actually decrease the performance of your application
- Single Points of Failure: While a load balancing can be used to eliminate single points of failure, poorly planned load balancing can actually add more single points of failure. Load balancing is enhanced with the inclusion of a second load-balancer with a static IP in front of the pair that sends traffic to one or the other depending on availability.
Related Tutorials
- An Introduction to HAProxy and Load Balancing Concepts
- How To Implement SSL Termination With HAProxy on Ubuntu 14.04
- How To Use HAProxy As A Layer 7 Load Balancer For WordPress and Nginx On Ubuntu 14.04
- Understanding Nginx HTTP Proxying, Load Balancing, Buffering, and Caching
- How To Create Your First DigitalOcean Load Balancer
- How To Use Reserved IPs
4. Monitoring
Monitoring can support a server environment by tracking the status of services and the trends of your server resource utilization, thus providing great visibility into your environment. One of the biggest benefits of monitoring systems is that they can be configured to trigger an action, such as running a script or sending a notification, when a service or server goes down, or if a certain resource, such as CPU, memory, or storage, becomes over-utilized. These notifications enable you to react to any issues as soon as they occur, which can help minimize or prevent the downtime of your application.
Required for Production? Not necessarily, but the need for monitoring increases as a production environment grows in size and complexity. It provides an easy way to keep track of your critical services and server resources. In turn, monitoring can improve the recoverability, and inform the planning and maintenance of your setup.
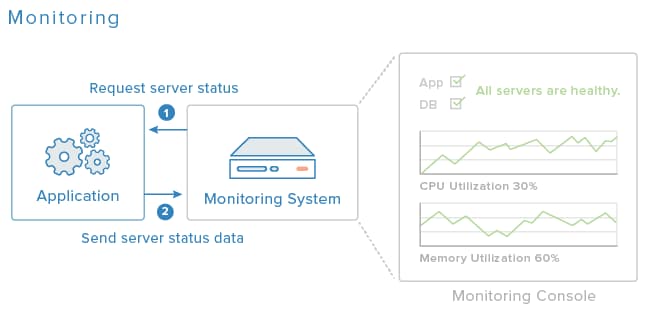
The diagram above is an example of a monitoring system. Typically, the monitoring server will request status data from agent software running on the application and database servers, and each agent will respond with software and hardware status information. The administrator(s) of the system can then use the monitoring console to look at the overall state of the application, and drill down to more detailed information, as needed.
Considerations
- Services to Monitor: The services and software that you will monitor. Minimally, you should monitor the state of all of the services that need to be in a healthy running state for your application to function properly
- Resources to Monitor: The resources that you will monitor. Examples of resources include CPU, memory, storage, and network utilization, and the state of server as a whole
- Data Retention: The period of time that you retain monitoring data before discarding it. This, along with your choice of items to monitor, will affect the amount of disk space that your monitoring system will require
- Problem Detection Rules: The thresholds and rules that determine whether a service or resource is in a OK state. For example, a service or server may be considered to be healthy if it is running and serving requests, whereas a resource, such as storage, might trigger a warning if its utilization reaches a certain threshold for a certain amount of time
- Notification Rules: The thresholds and rules that determine if a notification should be sent. While notifications are important, it is equally important to tune your notification rules so that you don’t receive too many; an inbox full of warnings and alerts will often go ignored, making them almost as useless as no notifications at all
Related Tutorials
- How To Install Nagios 4 and Monitor Your Servers on Ubuntu 14.04
- How To Use Icinga To Monitor Your Servers and Services On Ubuntu 14.04
- How To Install Zabbix on Ubuntu & Configure it to Monitor Multiple VPS Servers
- Monitoring and Managing your Network with SNMP
- How To Configure Sensu Monitoring, RabbitMQ, and Redis on Ubuntu 14.04
5. Centralized Logging
Centralized logging can support a server environment by providing an easy way to view and search your logs, which are normally stored locally on individual servers across your entire environment, in a single place. Aside from the convenience of not having to log in to individual servers to read logs, centralized logging also allows you to easily identify issues that span multiple servers by correlating their logs and metrics during a specific time frame. It also grants more flexibility in terms of log retention because local logs can be off-loaded from application servers to a centralized log server that has its own, independent storage.
Required for Production? No, but like monitoring, centralized logging can provide invaluable insight into your server environment as it grows in size and complexity. In addition to being more convenient than traditional logging, it enables you to rapidly audit your server logs with greater visibility.
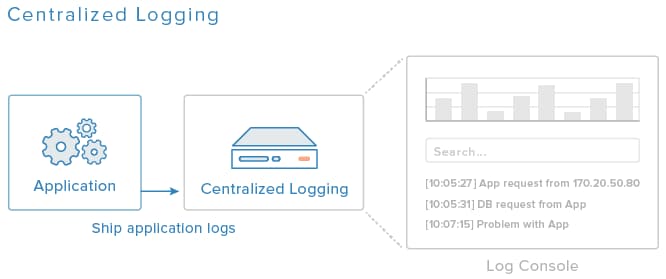
The diagram above is a simplified example of a centralized logging system. A log shipping agent is installed on each server, and configured to send important app and database logs to the centralized logging server. The administrator(s) of the system can then view, filter, and search all of the important logs from a single console.
Considerations
- Logs to Gather: The particular logs that you will ship from your servers to the centralized logging server. You should gather the important logs from all of your servers
- Data Retention: The period of time that you retain logs before discarding them. This, along with your choice of logs to gather, will affect the amount of disk space that your centralized logging system will require
- Log Filters: The filters that parse plain logs into structured log data. Filtering logs will improve your ability to query, analyze, and graph the data in meaningful ways
- Server Clocks: Ensure that the clocks of your servers are synchronized and using set to the same time zone, so your log timeline is accurate across your entire environment
Related Tutorials
Conclusion
When you put all the components together, your production environment might look something like this:
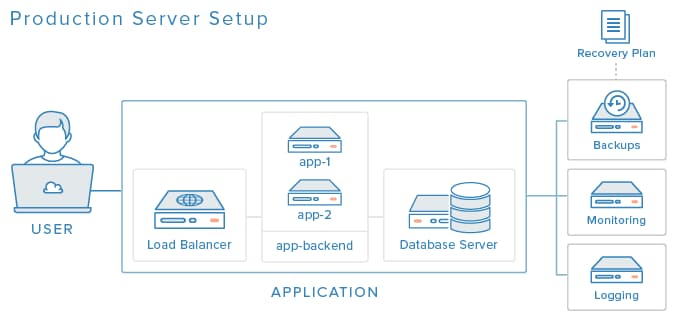
Now that you are familiar with components that can be used to support and improve a production server setup, you should consider how you can integrate them your own server environments. Of course, we didn’t cover every possibility, but this should give you an idea of where to get started. Remember to design and implement your server environment based on a balance of your available resources and your own production goals.
If you are interested in setting up an environment like the one above, check out this tutorial: Building for Production: Web Applications.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Software Engineer @ DigitalOcean. Former Señor Technical Writer (I no longer update articles or respond to comments). Expertise in areas including Ubuntu, PostgreSQL, MySQL, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Great artictle! I would like to see more production-ready articles
thanks for the great effort
how many droplets this configuration needs? the minimum confiuration and how to scale it with time when the traffic/storage is getting bigger?
Manicas, congatulations my friend, excelent tutorial!!!, here in Chile Digital Ocean is very famouse platform, please follow makinf good things ;)
Re: Increase servers’ availability using Zabbix server 3.03
Dear Mitchell Anicas
Could you kindly help me how to “Increase servers’ availability” by using Zabbix server 3.03? please provide some information or web links for further reading. really really appreciate your help and comments.
Great article Mitchell. The back end is so important to keep all files secure. When sites and data are down, it also impacts organic SEO in a very negative way
Very informative, worth reading. In the recent, I having trouble with our serve, I don’t know how to integrate our server an with that I contacted computerserversupport.com to fix everything. Now after reading this post, I have now ideas on how it works. Thanks for that
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
